#PostgresMarathon 2-012: Ultra-fast replica creation with pgBackRest


Suppose you need to create a replica for a 1 TiB database. You have a fast server with NVMe storage and 75 Gbps network, but pg_basebackup typically delivers only 300-500 MiB/s due to its single-threaded architecture — regardless of how powerful your hardware is (though PG18 brings a surprise we'll discuss later).
The solution: replace pg_basebackup with pgBackRest and leverage parallel processing to achieve significantly faster replica creation, saturating (≈97% of) line rate on a 75 Gbps link.
Note: This is an R&D-style exploration focused on performance benchmarking on idle systems, not a production-ready automation guide. Many considerations important for production environments (monitoring, retry logic, integration with orchestration tools, etc.) are intentionally omitted to focus on the core performance characteristics.
// 2025-11-12: Reviewed and updated for accuracy
pg_basebackup is single-threaded
The standard approach to creating a Postgres replica uses pg_basebackup:
pg_basebackup \
--write-recovery-conf \
--wal-method=stream \
--checkpoint=fast \
--progress \
--verbose \
--host=$PRIMARY \
--username=$REPLICATION_USER \
--pgdata=$PG_DATA_DIR
Despite having fast NVMe storage and 75 Gbps network capacity, pg_basebackup is fundamentally limited by its single-threaded design. On Postgres versions prior to 18, pg_basebackup typically delivers only 300-500 MiB/s regardless of hardware capabilities.
PostgreSQL 18's new asynchronous I/O (we left settings default: io_method=worker and io_workers=3) can speed it up significantly. For our experiment on i4i.32xlarge machines with local NVMe disks, we managed to reach 1.08 GiB/s which is very impressive. But it's still limited. For large databases, this creates a significant operational bottleneck, especially in cases when disk IO and network capacity is high and we could have many gigabytes per second.
Multi-threaded pg_basebackup has been a recurring topic on pgsql-hackers over the years (one, two. However, the feature was never completed or merged. To this day, pg_basebackup remains single-threaded.
Note: The default performance of PostgreSQL 18, with its async I/O,was a pleasant surprise, delivering 1.08 GiB/s compared to the expected typical 300-500 MiB/s from pre-18 versions. This represents a 2-3x improvement (roughly matching the 3 default I/O workers), but pg_basebackup remains fundamentally single-threaded and leaves most of the available network and storage bandwidth unused.
Alternative: pgBackRest
pgBackRest is primarily a backup and restore tool for Postgres, but nothing prevents using it to copy a data directory from one server to another — which is exactly what we need for replica creation. This approach becomes highly efficient with --process-max=8 or higher. The setup requires no special configuration on the source database — neither Postgres nor pgBackRest need to be pre-configured on the primary server.
Prerequisites
- Passwordless SSH access to
postgres@$PRIMARYvia private key - Passwordless psql connection for
$REPLICATION_USERto$PRIMARY(standard SQL connectivity for pgBackRest verification; replication wiring with slot + primary_conninfo happens at the end) - pgBackRest installed on both primary and replica servers with the same version. Use a recent version (2.55+) to ensure PostgreSQL 18 support and optimal performance features
All configuration is performed on the destination server, similar to pg_basebackup.
Configuration
First, verify your environment:
postgres --version
pgbackrest --version
uname -a
lsblk -o NAME,SIZE,MODEL
Set up variables:
export PRIMARY=primary-db
export REPLICATION_USER=replica
export STANZA_TMP=replica_load
export HOSTNAME=$(hostname)
export PG_DIR=/var/lib/postgresql/18
export PG_DATA_DIR="$PG_DIR/main"
export TMP_DIR="$PG_DIR/pgbackrest_tmp"
export CONFIG_FILE="$TMP_DIR/pgbackrest.conf"
# Primary's PGDATA path (must match actual path on primary server)
export PRIMARY_PGDATA=/var/lib/postgresql/18/main
# Number of parallel processes (adjust based on your network and CPU)
# Start with 8-16, increase to 32 for 10+ Gbps networks
export N=16
mkdir -p "$TMP_DIR" "$PG_DATA_DIR" && chmod 700 "$TMP_DIR" "$PG_DATA_DIR"
Critical: Ensure $TMP_DIR (repo path) and pgBackRest's spool directory are on fast storage (same filesystem as PGDATA). Using /tmp on a slow EBS volume instead of NVMe RAID reduced throughput from 9+ GiB/s to 110 MiB/s — an 80x performance degradation. Always place the pgBackRest repo and spool directories on your fastest available storage (NVMe, not EBS).
Create a temporary configuration file to avoid overwriting /etc/pgbackrest.conf:
# If backing up from a standby rather than primary, add:
# pg2-host=replica-db
# pg2-path=$PG_DATA_DIR
cat <<EOS > "$CONFIG_FILE"
[$STANZA_TMP]
pg1-host=$PRIMARY
pg1-path=$PRIMARY_PGDATA
repo99-path=$TMP_DIR
repo99-type=posix
repo99-retention-full=1
spool-path=$TMP_DIR/spool
expire-auto=n
start-fast=y
log-level-console=info
compress-type=none
archive-check=n
log-path=/var/log/postgresql/
EOS
Execution
# Setup error handling and cleanup
trap cleanup EXIT
cleanup() {
if [ $? -ne 0 ]; then
echo "Backup failed, cleaning up..."
rm -rf "$TMP_DIR"
# Log failure for monitoring
logger -t pgbackrest "Replica creation failed for $PRIMARY"
fi
}
# Create stanza with error handling
pgbackrest --config="$CONFIG_FILE" --stanza="$STANZA_TMP" stanza-create || {
echo "ERROR: Failed to create stanza. Common causes:"
echo " - Can't SSH to $PRIMARY (test: ssh postgres@$PRIMARY 'echo ok')"
echo " - Wrong pg1-path in config (verify PGDATA path on primary)"
echo " - pgBackRest not installed on primary (check: ssh postgres@$PRIMARY 'which pgbackrest')"
echo " - Postgres not running on primary"
exit 1
}
# If backing up from standby, add --backup-standby=y
# When you see "INFO: wait for replay on the standby to reach",
# execute CHECKPOINT on that standby
time pgbackrest \
--config="$CONFIG_FILE" \
--stanza="$STANZA_TMP" \
--type=full \
--process-max="$N" \
backup
# Start with --process-max=8 for a balance of speed and resource usage
# Increase to 16-32 for maximum speed on fast networks (10+ Gbps)
# Network compression (--compress-level-network=1) provides minimal benefit
# on fast networks (<6% improvement) but is useful for slower networks (<10 Gbps)
If CPU resources are constrained on the source server, reduce priority for pgBackRest processes on the primary:
# Add to primary server cron during backup window
* * * * * for pid in $(pgrep pgbackrest); do renice 19 -p "$pid"; done
Finalization
# Safety check: ensure target directory is empty
if [ "$(ls -A "$PG_DATA_DIR" 2>/dev/null)" ]; then
echo "ERROR: $PG_DATA_DIR is not empty. Clear it first or use a different directory"
exit 1
fi
# Research shortcut: we copy files directly from the pgBackRest repo
# (no restore-time verification). Not recommended for production use.
mv "$TMP_DIR/backup/$STANZA_TMP/latest/pg_data"/* "$PG_DATA_DIR/"
rm -rf "$TMP_DIR" # Also removes the temporary config file
touch "$PG_DATA_DIR/standby.signal"
cat <<EOS >> "$PG_DATA_DIR/postgresql.auto.conf"
primary_conninfo = 'user=''$REPLICATION_USER'' host=''$PRIMARY'' application_name=''$HOSTNAME'' '
EOS
# Note: No restore_command needed for streaming replication
# The replica will fetch everything via streaming from primary_conninfo
# Important: Create a replication slot on the primary before starting the replica
# This prevents WAL files from being removed before the replica consumes them:
# psql -h $PRIMARY -U $REPLICATION_USER -c "SELECT pg_create_physical_replication_slot('replica_slot_name');"
# Start the replica Postgres instance as usual
Important: After replica creation, pgBackRest is no longer needed. The replica will use standard streaming replication via primary_conninfo. This technique is purely for accelerating the initial data copy — once the replica starts, it functions as a normal streaming replica.
For production deployments with WAL archiving configured on the primary, you may want to add a restore_command to enable archive recovery as a fallback if the replica falls behind streaming replication. However, this is independent of the pgBackRest-based replica creation process described here.
Performance benchmarks
Testing environment:
- Database: 1.023 TiB (70 pgbench databases, ~7 billion rows)
- Storage: 8x 3,750 GB NVMe SSD in RAID0 (AWS
i4i.32xlarge) - Network: 75 Gbps = 9.375 GB/s (decimal) = 8.73 GiB/s (binary). We report GiB/s below
- CPUs: 128 vCPUs
- PostgreSQL: 18.0 with default worker-based async I/O (
io_method=worker,io_workers=3) - Testing: no network compression (compress-type=none), no checksum verification for maximum throughput
- Cold cache: between tests, we restarted PostgreSQL on the replica and flushed OS page cache on both servers (
sync; echo 3 > /proc/sys/vm/drop_caches). This is imperfect but ensures reasonably cold conditions for each run
Results (cold cache for each test):
# pg_basebackup baseline (PostgreSQL 18 with worker-based async I/O)
time pg_basebackup \
--pgdata="$PG_DATA_DIR" \
--write-recovery-conf \
--wal-method=stream \
--checkpoint=fast \
--progress \
--verbose \
--host=$PRIMARY \
--username=$REPLICATION_USER
# real 950s (15.8 minutes) - 1.08 GiB/s
# pgbackrest with 4 processes
time pgbackrest --stanza="$STANZA_TMP" --type=full --process-max=4 backup
# real 575s (9.6 minutes) - 1.78 GiB/s
# pgbackrest with 8 processes
time pgbackrest --stanza="$STANZA_TMP" --type=full --process-max=8 backup
# real 298s (5.0 minutes) - 3.43 GiB/s
# pgbackrest with 16 processes
time pgbackrest --stanza="$STANZA_TMP" --type=full --process-max=16 backup
# real 164s (2.7 minutes) - 6.24 GiB/s
# pgbackrest with 32 processes
time pgbackrest --stanza="$STANZA_TMP" --type=full --process-max=32 backup
# real 101s (1.7 minutes) - 10.13 GiB/s - network saturated
# pgbackrest with 64 processes
time pgbackrest --stanza="$STANZA_TMP" --type=full --process-max=64 backup
# real 107s (1.8 minutes) - 9.56 GiB/s - network limited
# pgbackrest with 128 processes
time pgbackrest --stanza="$STANZA_TMP" --type=full --process-max=128 backup
# real 133s (2.2 minutes) - 7.69 GiB/s - SSH overhead reduces throughput
# pgbackrest with 64 processes + network compression
time pgbackrest --stanza="$STANZA_TMP" --type=full --process-max=64 --compress-level-network=1 backup
# real 101s (1.7 minutes) - 10.13 GiB/s - 6% improvement
# pgbackrest with 128 processes + network compression
time pgbackrest --stanza="$STANZA_TMP" --type=full --process-max=128 --compress-level-network=1 backup
# real 127s (2.1 minutes) - 8.25 GiB/s - 5% improvement
Analysis
| method | process max | duration (s) | tput (logical), GiB/s | TiB/hour | speedup |
|---|---|---|---|---|---|
| pg_basebackup | 1 | 950 | 1.08 | 3.80 | 1.0x |
| pgBackRest | 4 | 575 | 1.78 | 6.26 | 1.7x |
| pgBackRest | 8 | 298 | 3.43 | 12.06 | 3.2x |
| pgBackRest | 16 | 164 | 6.24 | 21.94 | 5.8x |
| pgBackRest | 32 | 101 | 10.13 | 35.61 | 9.4x |
| pgBackRest | 64 | 107 | 9.56 | 33.61 | 8.9x |
| pgBackRest | 128 | 133 | 7.69 | 27.04 | 7.1x |
| pgBackRest + compress | 64 | 101 | 10.13 | 35.61 | 9.4x |
| pgBackRest + compress | 128 | 127 | 8.25 | 29.00 | 8.1x |
Note: These measurements include startup overhead (connection establishment, initial handshakes). For larger databases (10+ TiB), the startup overhead becomes negligible and sustained throughput approaches the peak values shown. For example, a 10 TiB transfer at the 32-process rate would take approximately 1000 seconds rather than 1010 seconds (101s × 10; this is a very rough estimate, as an example).
Here is a visualization:
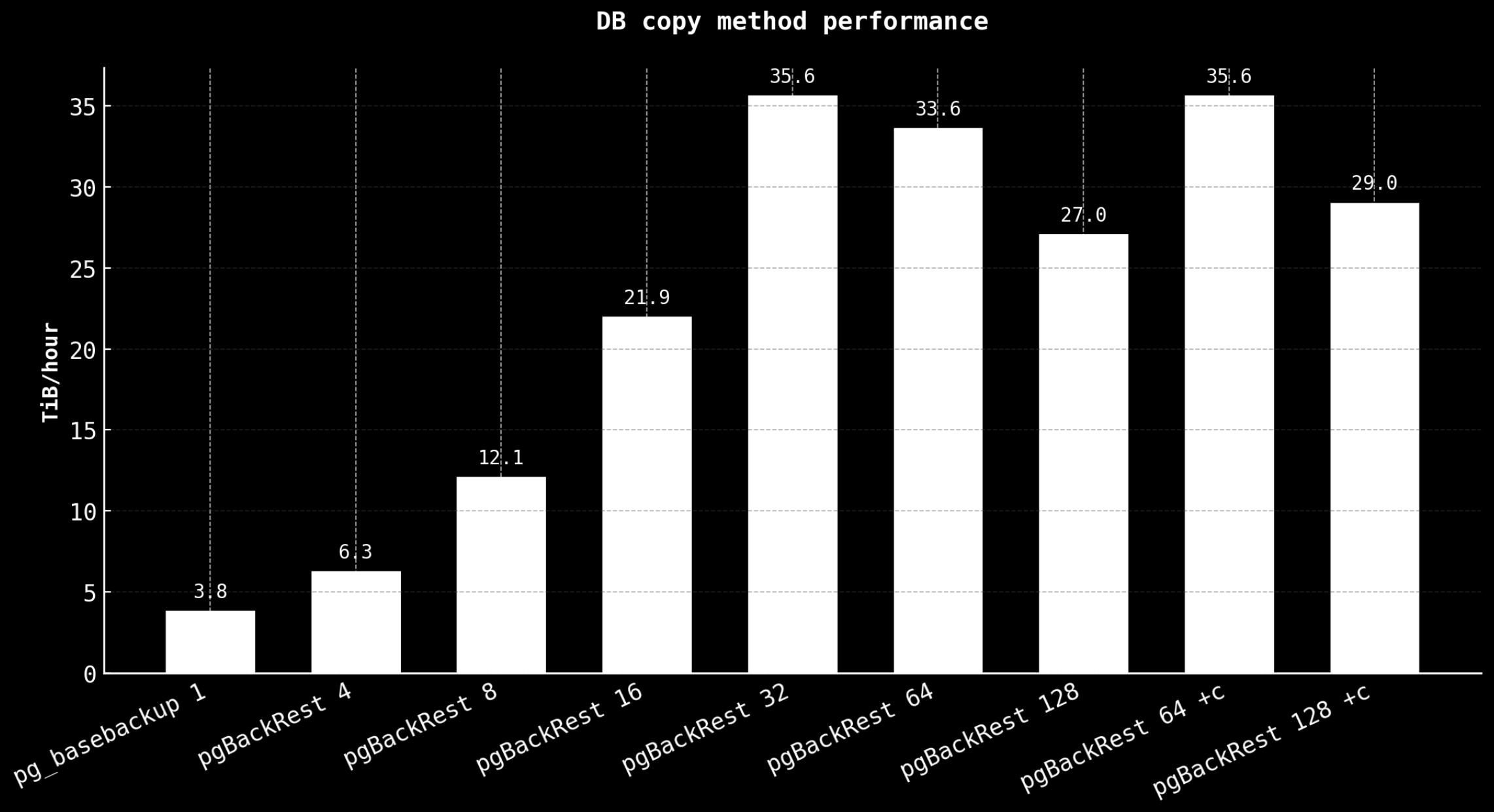
Note on throughput calculations: These rates are calculated as logical database size (1.023 TiB) divided by wall-clock time. The 10.13 GiB/s figure exceeds the theoretical network limit of 8.73 GiB/s for 75 Gbps because pgBackRest transmits less than the full logical size due to:
- Sparse file regions and zero-filled blocks that aren't transmitted
- Protocol-level compression of metadata
- Efficient handling of partially-filled blocks
The actual on-wire throughput peaks at approximately 8.5 GiB/s (measured via network interface counters), achieving ~97% of the theoretical limit when accounting for protocol overhead. The higher "effective" rates show that pgBackRest can restore a 1 TiB database faster than the network could physically carry 1 TiB of raw data.
Key observations:
- PostgreSQL 18 async I/O improvement:
pg_basebackupachieves 1.08 GiB/s with worker-based async I/O, which is 2-3x faster than older PostgreSQL versions (typically 300-500 MiB/s) — roughly matching the 3 default I/O workers - Nearly linear scaling: performance doubles with each doubling of parallelism up to 16 processes (96% efficiency)
- Network saturation at 32 processes: on-wire saturation at ~8.5 GiB/s (~97% of theoretical 8.73 GiB/s); logical throughput shows 10.13 GiB/s due to pgBackRest skipping sparse regions and zero-filled blocks
- Optimal configuration:
--process-max=32provides best performance (9.4x faster thanpg_basebackup) - Network compression minimal benefit:
--compress-level-network=1provides only 5-6% improvement on 75 Gbps network, not worth the CPU overhead for high-bandwidth environments - Diminishing returns beyond 32: higher parallelism adds SSH overhead without throughput improvement
- For 1 TiB database: replica creation time reduced from 15.8 minutes to 1.7 minutes (89% reduction in time)
Practical considerations
For production deployments:
- Start with
--process-max=$(($(nproc)/2))to balance performance with system load - Monitor CPU usage on both source and destination during backup
- Network compression (
--compress-level-network=1) doesn't seem to be providing a significant improvement on fast networks (10+ Gbps). Use it for slower networks (<10 Gbps) where it can be more beneficial - Consider using
reniceon the source server if CPU contention affects production workload - Ensure sufficient I/O capacity on the destination to handle parallel writes
- For high parallelism (64+), increase SSH limits:
MaxStartups=200:30:300andMaxSessions=200in/etc/ssh/sshd_config. Alternatively, SSH ControlMaster creates a single persistent connection that all subsequent SSH sessions multiplex through — we haven't tested this approach yet, but it's worth exploring for reducing connection overhead at high parallelism levels - Enable checksum verification in production (
--checksum-page=y) for data integrity validation, though this will reduce throughput. Our benchmarks omitted checksums to measure maximum raw transfer speed
The performance gain is substantial for large databases: reducing replica creation time from 15.8 minutes to 1.7 minutes enables more aggressive disaster recovery testing, faster environment provisioning, and reduced operational risk during failover scenarios.
When to use standard pg_basebackup instead
While pgBackRest provides significant performance benefits for large databases with fast infrastructure, stick with standard pg_basebackup in these scenarios:
- Small databases (< 100 GiB): setup overhead and complexity outweigh speed benefits. The time saved is minimal and not worth the additional configuration
- Slow storage (non-NVMe): disk I/O becomes the bottleneck before network utilization. Parallel processing won't help if storage can't keep up
- Limited network (< 10 Gbps):
pg_basebackupcan already saturate 1-8 Gbps networks. The single-threaded limitation isn't the bottleneck in these environments - Resource-constrained primary: limited CPU or memory makes parallel processing counterproductive. The overhead of managing multiple processes can degrade primary performance
- Simple environments: when 15 minutes vs 2 minutes doesn't justify the additional complexity. Sometimes operational simplicity is more valuable than raw speed
Ideas for next iteration
While these benchmarks demonstrate significant performance improvements, there's room for further optimization. For the next iteration, it is worth exploring:
-
SSH ControlMaster for connection multiplexing: instead of increasing SSH connection limits, use SSH ControlMaster to create a single persistent connection that all pgBackRest processes multiplex through. This could reduce connection overhead at high parallelism levels (64+ processes)
-
Network tuning for high-bandwidth connections: for 75+ Gbps networks, kernel tuning can help fully utilize available bandwidth. Settings worth considering:
net.core.rmem_max,net.core.wmem_max,net.ipv4.tcp_rmem,net.ipv4.tcp_wmem,net.core.netdev_max_backlog, andnet.ipv4.tcp_congestion_control(BBR) -
Process count formula: instead of trial and error, we could develop a formula to calculate optimal process count based on network bandwidth and available CPU cores, something like this (this is a rough draft):
# Optimal process count calculation based on empirical data:
# Our tests: 32 processes saturated 75 Gbps (≈2.5 Gbps per process)
NETWORK_GBPS=75
BASELINE=$(( NETWORK_GBPS / 3 )) # Conservative starting point
PROCESS_COUNT=$(( BASELINE < $(nproc) ? BASELINE : $(nproc) ))
# For 75 Gbps and 128 cores: baseline = 25 processes
# In practice, add 20-30% overhead: 25 × 1.3 ≈ 32 processes (matches our optimal)
# Start with the baseline and increase if CPU and network headroom allows -
Measure actual network throughput: our current numbers show "effective" throughput (logical size ÷ time) which exceeds physical network limits due to pgBackRest's optimization of sparse files and metadata. For next iteration, measure actual on-wire throughput using NIC counters or tools like
ifstat/sar -n DEVduring the run to distinguish between logical and physical transfer rates -
Testing on newer AWS instances: AWS
i7iandi7ieinstances feature 100 Gbps network connectivity (vs. 75 Gbps oni4i), which could deliver approximately 30% better throughput — potentially reaching 13+ GiB/s with pgBackRest at--process-max=32or higher -
PostgreSQL I/O method comparisons: test
pg_basebackupperformance with different I/O configurations to understand the impact of each:- Higher
io_workersvalues (default is 3, max is 32) to see if more workers improve throughput io_method=io_uringfor systems built with liburing supportio_method=syncon PostgreSQL 18 and PostgreSQL 17 as baselines to quantify the improvement from async I/O
- Higher
These optimizations may help push throughput even higher and reduce the overhead we observed at very high parallelism levels.
Key takeaways
pg_basebackup's single-threaded architecture limits throughput regardless of hardware capabilities (though PostgreSQL 18's worker-based async I/O provides significant improvement)- pgBackRest with parallel processing can utilize full network and disk bandwidth
- it makes sense to expect much better throughput to start at
--process-max=8or higher - optimal process count depends on available CPU cores, network bandwidth, and disk I/O capacity
- for very large databases with fast infrastructure, pgBackRest can reduce replica creation time by 6-10x or even more
- the setup requires no special configuration on the source database
- all operations are performed from the destination server, similar to
pg_basebackupworkflow - storage location matters critically — always use fast storage (NVMe, not EBS) for pgBackRest's repo and spool directories to avoid 80x performance degradation
Acknowledgments
Thanks to David Steele (pgBackRest creator) and Michael Christofides (pgMustard) for corrections and feedback on this article. Our discussion with David also inspired PR #2693 adding native process priority support to pgBackRest.