Postgres.AI Bot. Towards LLM OS for Postgres

I'm happy to present our new product, Postgres.AI Bot. It is powered by OpenAI's GPT-4 Turbo and is designed to help engineers improve their experience when working with PostgreSQL. This bot has a vast knowledge base with over 110,000 entries, including documentation, source code for different PostgreSQL versions, and related software like PgBouncer, Patroni, and pgvector. It also integrates expert articles and blogs.
In addition, the bot can conduct two types of experiments to verify ideas:
- Single-session on thin clones provided by Postgres.AI DBLab Engine to check SQL syntax and behavior of PostgreSQL planner and executor, and
- Full-fledged benchmarks (pgbench) on separate VMs in Google Cloud to study Postgres behavior under various workloads. For each iteration, 70+ artifacts are automatically collected and used by the bot to analyze and visualize experiment results.
Our ambitious goal for 2024 – conduct 1 million database experiments in both shared and dedicated environments, aiding both the bot's knowledge and the improvement of these projects, particularly in performance. To achieve this, we became a part of Google Cloud's AI startup program.
In this blog post, we discuss some details of how the bot is implemented, what it is capable of, share its first exciting achievements, and talk about the future.
Concept
GPT-4, launched in March 2023, opened up new possibilities across various fields. Our mission at Postgres.AI is to enhance the experience of working with Postgres for engineers, making it faster to become proficient.
Typically, it takes about 10 years to become a "Postgres expert", and I always said this should not be so. Prior to 2023, we developed several tools to address this challenge, with DBLab Engine being the key one. This tool facilitates database branching and allows engineers to develop and test with full-size, cost-effective writable Postgres clones. With a full-size writable database in hand, any engineer can start learning SQL and Postgres aspects drastically faster.
With LLM, we can go even further. Much further.
The concept is straightforward: any question an engineer has can be answered by the LLM, but we need to ensure the answers are reliable and grounded, we need to minimize the risks of false positives (a.k.a. "hallucinations"). This is where RAG – retrieval augmented generation – comes in. Our RAG knowledge base (RAG KB), currently with over 110,000 items, includes documentation, source code, and high-quality how-to articles for Postgres and its major software.
In November 2023, Andrej Karpathy released an insightful 1-hour introduction video, where he discussed the concept of "LLM OS":
LLM OS. Bear with me I'm still cooking.
— Andrej Karpathy (@karpathy) November 11, 2023
Specs:
- LLM: OpenAI GPT-4 Turbo 256 core (batch size) processor @ 20Hz (tok/s)
- RAM: 128Ktok
- Filesystem: Ada002 pic.twitter.com/6n95iwE9fR
This sparked our "aha" moment. It perfectly aligned with what we were already working on: placing LLM at the core, surrounded by tools to streamline various tasks for Postgres engineers. These tasks include checking documentation, delving into source code when necessary, testing SQL queries across different Postgres versions, reproducing bugs, and conducting benchmarks. Inspired by this, we started prototyping LLM OS for Postgres.
Fundamental principles
In developing this system, we adhere to two critical consulting principles I established during my Postgres consulting career.
Consulting principle #1: High-quality sources
We always need to rely on reliable sources of knowledge. These include:
- Documentation: The Postgres documentation is nearly flawless.
- Source Code: The quality here is considered perfect for our purposes. Despite any bugs, inspecting the source code is invaluable for understanding the inner workings. The Postgres source code is notably well-commented and includes comprehensive READMEs.
- Credible articles and blog posts: Only from verified authors.
Transparency about our knowledge sources is crucial. We always credit the author and provide links to original materials. This practice is not just about respect; it also builds trust. Basing our reasoning on such solid foundations convinces others more effectively.
Consulting principle #2: Verification with DB experiments
A fundamental approach is to always question ideas and verify them through experimentation. This is particularly important to me. Establishing trust, especially at the beginning of a working relationship, can be challenging. Demonstrating concepts through experiments has consistently aided in building this trust.
It has always been important to validate my own ideas, which often led to refinements or the discovery of flaws.
Although experiments are enriching, they usually require significant effort. This challenge is addressed through automation. Our new Postgres.AI bot elevates experimenting with Postgres to a new level, saving considerable time and resources.
IVO – immediately validatable output
Another principle is one of the first lessons we have learned at Google AI Startup school, from Zack Akil: if the system you're building has IVO – immediately validatable output – then you're on a right path. It means that the generative AI (GenAI) output should be possible to quickly and easily validate. This idea is close to the Shift-left testing concept, and it is fully aligned with the 2nd consulting principle above.
This principle leads to two important conclusions for our case:
- Users who understand the risks of false positives in LLM answers (called "hallucinations" in the field of GenAI) and are ready to iterate achieve much better results. Therefore, our goal is to explain this to our users and offer them paths to iterate conveniently.
- LLM assistant systems working with programming code (such as GitHub Copilot) follow the IVO principle relatively easy, because it is usually not difficult to verify the generated code or code changes – it doesn't take time. But for the field of databases, there is "statefulness": to verify an idea reliably, we need to deal with large, realistic data sets. Postgres.AI's own solution to this problem is database branching provided by DBLab Engine – with it, the bot can iterate, obtaining clones/branches of multi-terabyte datasets in a few seconds, without extra costs at all.
Architecture
Here is a simple overview of the bot's system, followed by some specifics:
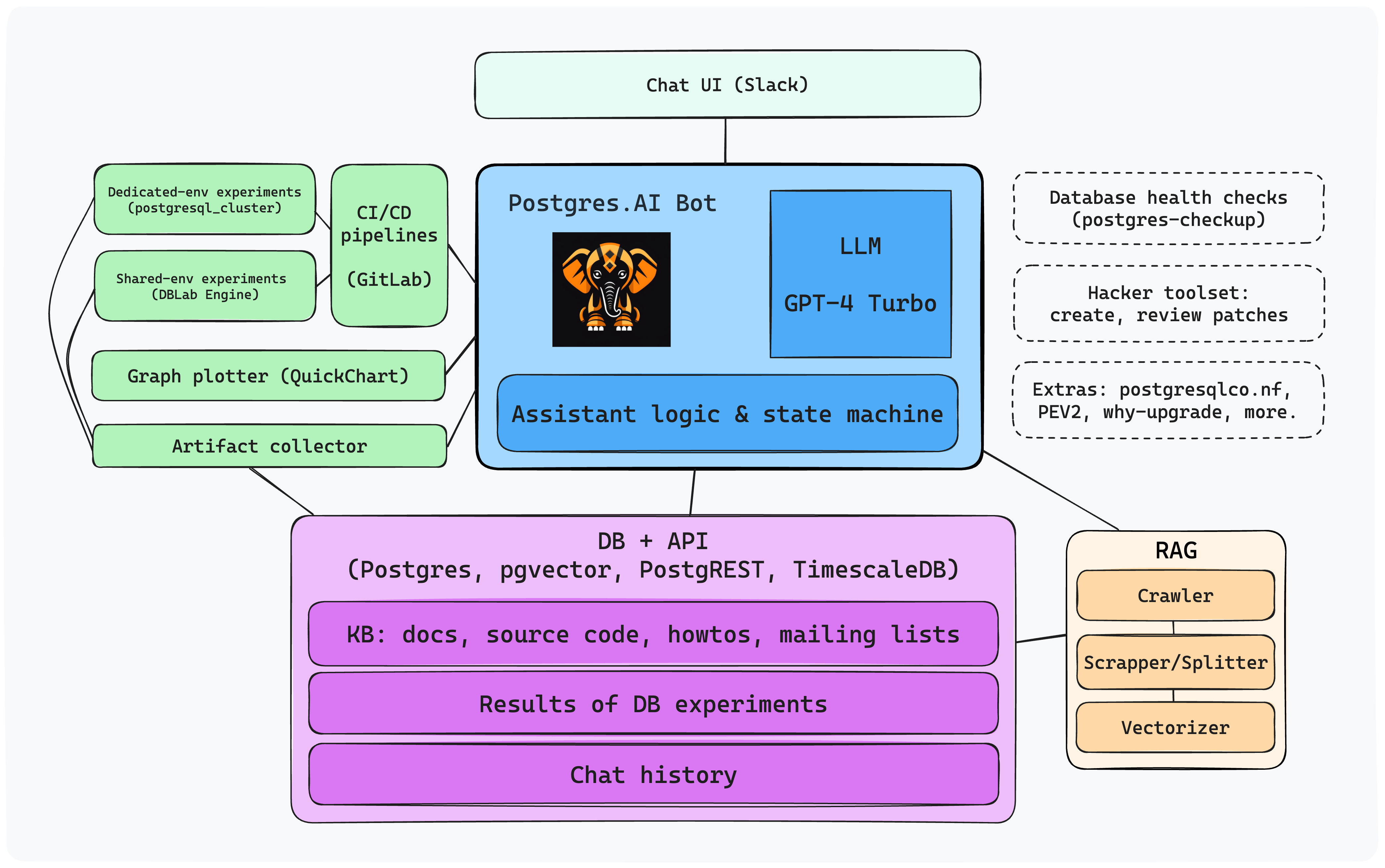
At the heart of the system, we have the LLM with "superprompt" (a standardized prompt used in all conversations for consistency), and the bot's main module written in Python. When choosing LLM, we decided to use the best currently available on the market: GPT-4 Turbo, in conjunction with OpenAI's Assistants API. This provides a state machine where each active conversation is in one of several states (or status; see the docs), such as queued, in_progress, requires_action, and others.
A key state is requires_action. In this state, the Assistant API is waiting for a response from the bot's main module, which can execute various functions. Currently, we have these:
get_extra_content– the primary RAG function for searching the RAG KB and compiling results.debug_mode– toggles debug mode on or off for a conversation thread.run_db_experiment_shared_env– conducts a database experiment in a shared environment (DBLab clone).run_db_experiment_dedicated_env– executes a database experiment in a dedicated environment (benchmark).run_db_experiment_wait– waits till the end of ongoing experiment and analyze results.make_a_plot– visualizes experiment results.fetch_whole_web_page– retrieves entire web pages from specific domains for inclusion in responses (limited to specific websites only).
Each function is driven by its own prompt and parameters. Interestingly, the LLM decides which function to call at each conversation step, which can involve multiple calls for a single answer or no calls at all. Here is an example:
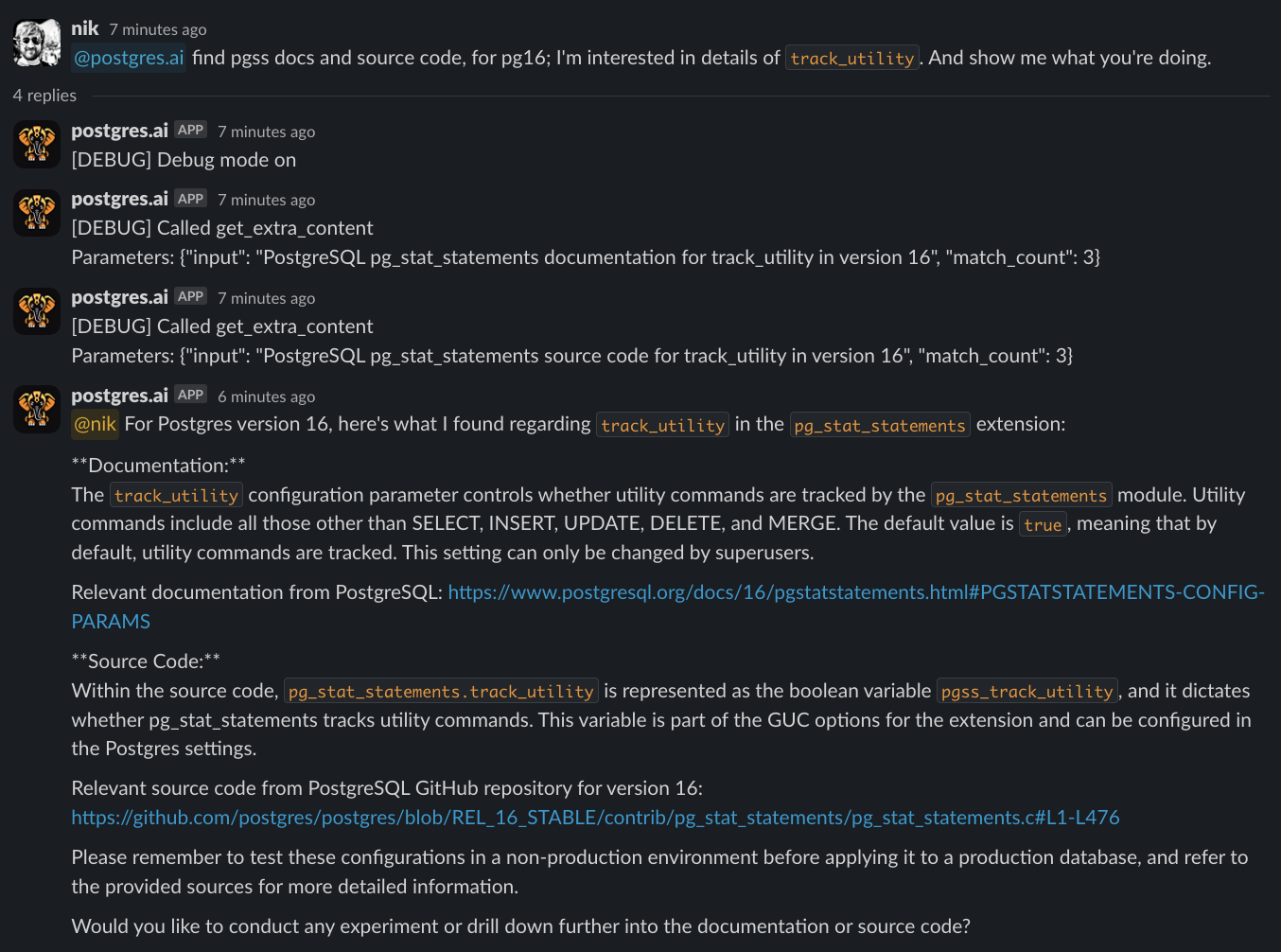
In this case:
- The query was to find docs and source code for
pg_stat_statementsin PostgreSQL 16. The bot correctly interpreted the jargon words I used. - A request for debug mode was also identified, though the request was not explicit.
- Consequently, it triggered three functions:
debug_mode, followed by twoget_extra_contentcalls. - The bot, guided by the "superprompt", suggested testing changes and offered to conduct an experiment, potentially exploring the impact of
pg_stat_statements.track_utility = onfor certain workloads.
Retrieval Augmented Generation (RAG)
RAG is implemented using these components:
- Database: Postgres and pgvector, running on Google Cloud's GKE.
- API: PostgREST provides a convenient and efficient way to turn our Postgres database into a RESTful API. This allows for seamless interaction and data retrieval.
- Custom Crawler and Scraper: These tools are designed to methodically collect and process a wide range of materials. This includes the documentation and source code for Postgres and related software like PgBouncer, pgBackRest, WAL-G, Patroni, pgvector. This ensures that our knowledge base is comprehensive and up-to-date.
- Vectorizer: using OpenAI API, it generates vectors for all content pieces, they are used in pgvector's similarity search.
Similarity search
For current size of the knowledge base, we are satisfied with performance of similarity search pgvector provides – and there is big room for growth: we still use IVFFlat and older version of pgvector. We plan to upgrade and start using HNSW before the KB reaches 1M entries. We also in talks with the Timescale team who develop their own solution, Timescale Vector, providing additional features for performance.
Mailing lists
After we launched alpha 1, we received multiple requests to include mailing lists to the KB. It makes sense: a lot of deep discussions, recipes, pieces of advice, bug reports – all this is present in the Postgres mailing list archives. It is not uncommon for a Postgres expert to search in mailing lists when troubleshooting some issue.
We're working on adding mailing list archives to the RAG KB. A challenging part of it is the level of trust that UGC has in general – unlike docs and source code, messages from places the mailing lists and similar other places are of unknown quality (unless we know it was Tom Lane speaking). To mitigate this, we start dividing content into groups:
- the highest level of trustworthiness: source code
- high level: docs, verified posts and articles, messages from well-known people
- unknown level: anything else
Authorship
From very beginning, being author of various posts and articles myself, I realized the problem of authorship. Thus, we developed a special approach for those who create great content related to Postgres:
- Our promise is that the bot, when using some content such as a blog post, mentions the author and provides a link to the original page – unlike "bare" ChatGPT that "remembers something" about the material and never mentions where it learned it from. This is possible thanks to RAG KB and embeddings.
- For blog posts and articles, we use the content only after explicit permission from the author.
Here is an example where the bot uses my own post:
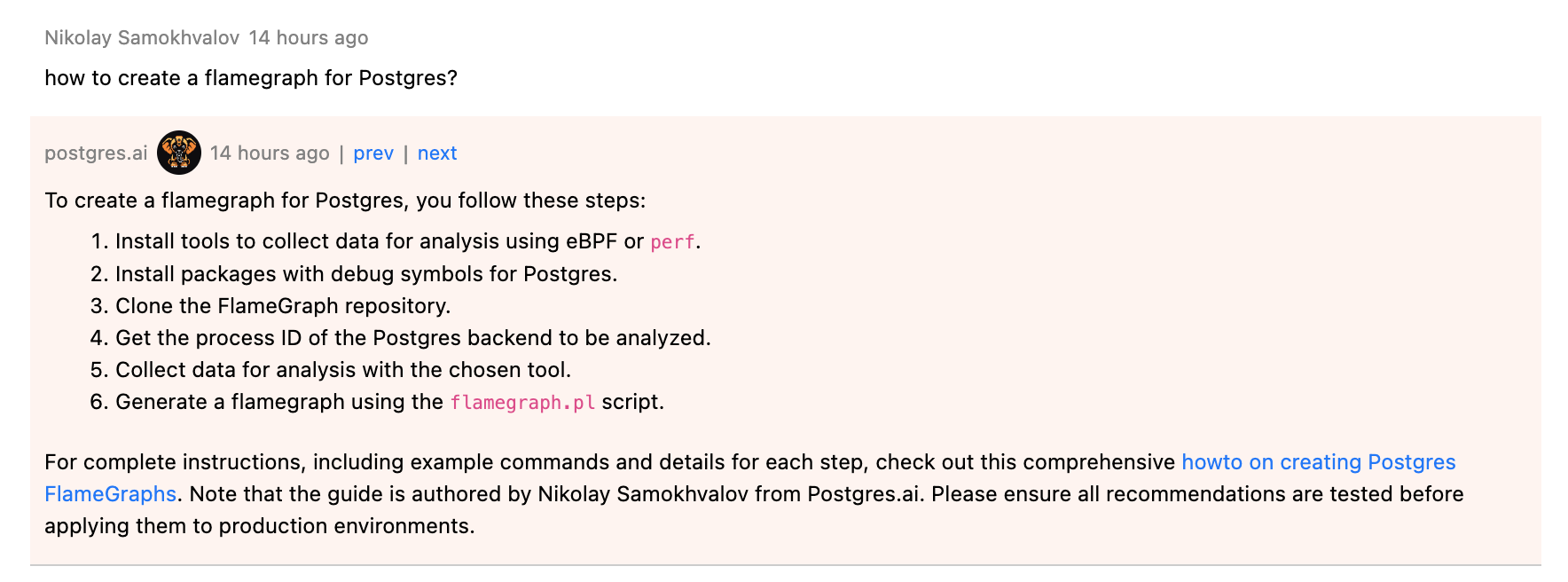
This approach is fully aligned with the first consulting principle we discussed above.
We started with these great sources:
- CYBERTEC blog – perhaps, the biggest source of Postgres howto articles, strongly oriented on practical tasks (I use it myself in my work for many years)
- OnGres blog – our partner, building great stuff such as StackGres
- Individual authors creating awesome content: Haki Benita, Franck Pachot.
Database experiments
To implement the second consulting principle, Verification, we decided to build two types of automation.
Shared-environment experiments
To check SQL or planner behavior, when one or two database connections are enough, it is ideal to conduct the experiment in a shared environment using thin clones provided by Postgres.AI DBLab Engine. We have 5 DBLab Engines set up for each Postgres major version currently supported (from 12 to 16), and the bot can request a new clone at any time, which takes ~1s to provide, benefiting from copy-on-write for data.
Dedicated-environment experiments
To study Postgres as a whole, to analyze the behavior of all its components such as the buffer pool, lock manager, we need experiments on separate VMs in GCP. Machine provisioning and software installation are managed by Autobase (formerly postgresql_cluster); it installs the needed version of Postgres, Patroni, various extensions, including those used for observability. Experiments are conducted using pgbench or psql, depending on the needs. Optionally, the bot can request installation of arbitrary software, compile a patched version from source code, tune Postgres, and much more. Although postgresql_cluster can provision a Patroni cluster consisting of multiple nodes, experiments are currently limited to only one node, the primary. An experiment can consist of multiple iterations. Before each iteration, caches (both page cache and Postgres buffer pool) are automatically flushed and cumulative statistic system is reset. After each iteration, artifacts are automatically collected and stored in the PostgresAI database, for further analysis.
All automation is done via GitLab pipelines. For each experimentation step, we collect 70+ artifacts such as information about machine, Postgres version, all settings, content of all pg_stat_*** views. You can find an example in this GitLab pipeline's data (artifacts have since expired; the job page is still available).
Google Cloud AI Startup Program
Recently, Postgres.AI was accepted to Google Cloud's AI startup program, receiving $350k in cloud credits, as well as access to other benefits. This is a great help for us, allowing us to move faster in bot development, research, and knowledge base growth.
1 million database experiments
We have started the "1 million database experiments" project. We have already conducted several hundred experiments and currently are preparing to expand in various areas:
- study Postgres planner behavior (various versions, settings, workloads)
- compare Postgres performance on different platforms (e.g., Intel, AMD, and ARM), operation systems, file systems, and so on
- understand the overhead of using various extensions, especially observability tools like pg_stat_statements
- benchmark various Postgres-related open-source tools in the areas such as connection pooling, backups, message queue
- collect the database of various edge and corner cases, demonstrating potential issues – for example, the behavior of subtransactions or LWLock:LockManager spikes.
One of the very first results obtained was achieving 2 million TPS on a single Postgres 16 node running on 4th-gen AMD EPYC with 360 vCPUs:
2 million TPS
— PostgresAI (@postgres_ai) January 17, 2024
Postgres 16, SELECT-only pgbench (w/o prepared statements), 4th-gen AMD EPYC with 360 vCPUs in GCP https://t.co/vtu0WhlibN pic.twitter.com/3Ji89Ed90Z
When working on this, chatting with the bot, we have obtained 2 interesting findings:
First, we needed to remove extension pg_stat_kcache, which provides physical-level metrics (CPU, disk IO) for query analysis. The extension maintainers quickly reacted to this finding with a fix — version 2.2.3 does not have this overhead. Of course, we asked the bot to test it again:
🪄 Magic continues with @postgres_ai :
— Nikolay Samokhvalov (@samokhvalov) January 19, 2024
- @Adrien_nayrat raises the question about pg_stat_kcache overhead
- @VKukharik shares details in https://t.co/YC3FmCiDqZ
- @rjuju123 issues a fix in a few hours
- @VKukharik and @postgres_ai test with patch, success!
I explored the patch… https://t.co/dJyI2e4zPY pic.twitter.com/TQaIvYUUBY
The second issue is related to pg_stat_statements, standard de facto tool for query analysis in Postgres, used literally in every database we're dealing with. Surprisingly, working with the bot, we found out that in certain situations (when a lot of backends execute the same query), the performance overhead is drastically different on 4th-gen Intel Xeon Scalable ("Sapphire Rapids") and 4th-gen AMD EPYC. To understand this, we looked at FlameGraphs (details are in this issue; click on the FlameGraphs to explore them):
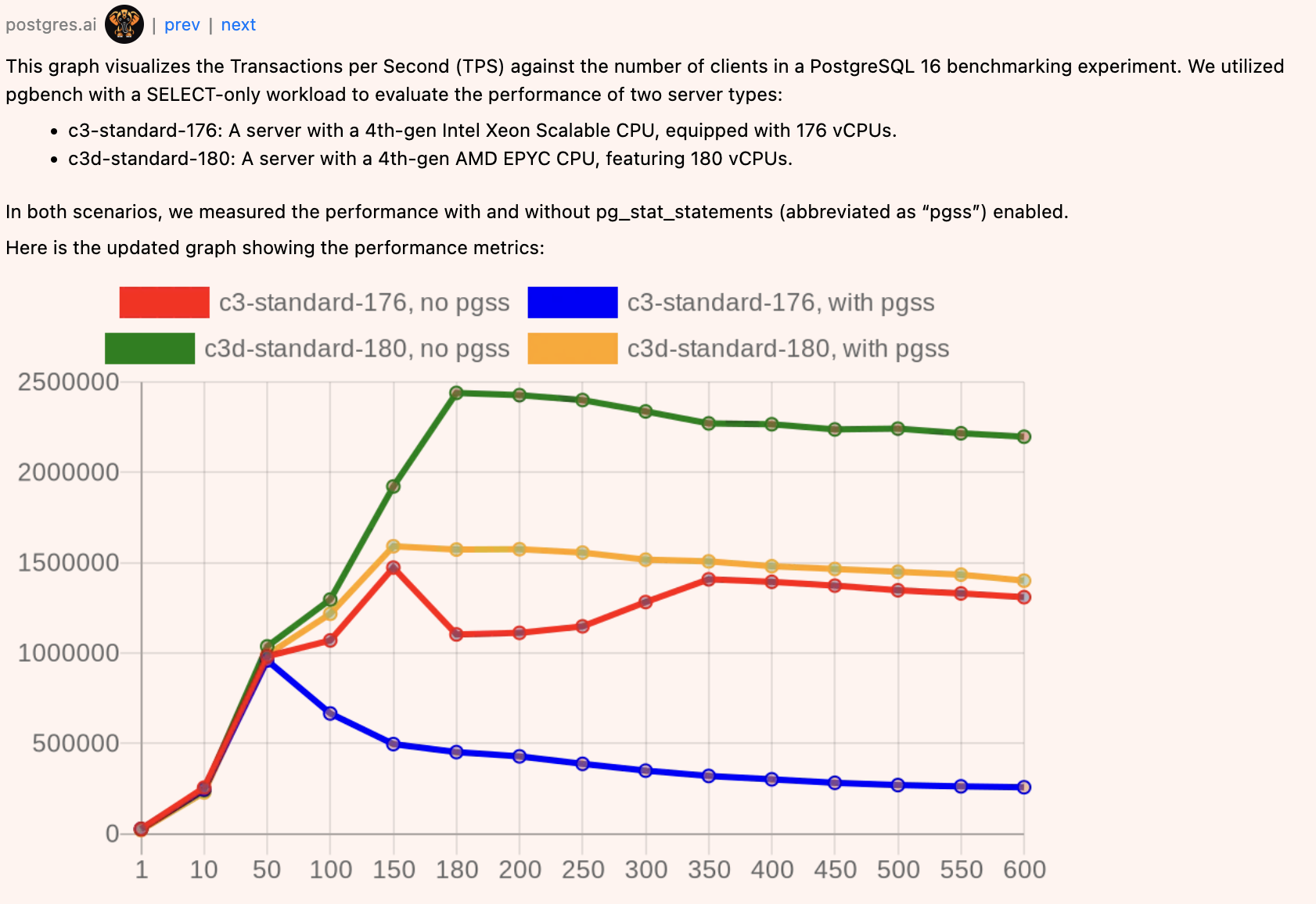


As we can see, on Intel, a lot of time is spent on s_lock. This issue needs further investigation and discussion; I briefly discussed it with several Postgres contributors, and two of them independently expressed an idea to implement sampling for pg_stat_statements.
Public by default
We strongly believe that Open Source plays key role in technological progress, and PostgreSQL, being one of the key projects in the Open Source ecosystem, should have more materials being open. If when talking to the bot, we produce an interesting result, it is worth sharing it with others (of course, if sensitive data is not involved into the discussion).
This is why by default, all communication is recorded to the Postgres.AI database and is publicly available, such as the example above: https://postgres.ai/chats/018d42c9-3a42-7c6d-a72e-364a7651fc1c. Not only Q&A sessions with the bot – synthetic experiments (those not including sensitive data) are shared too.
Paid version – "PRO"
We experiment with various business models. The first option we have developed is the "PRO" plan that currently costs $500/month ($300 with current promotional offer) and suits well for smaller teams.
It includes the following:
- private channel in Slack
- private communication
- up to 10 teammates can join the channel and participate in discussions with the bot
- high total limit on messages: 1,000 requests/month
- human support on the bot and Postgres-related topics with response time up to 3 business days
To learn more, please reach out to the team at [email protected].
First feedback
We have received very positive feedback from early adopters. Many of them are constantly checking the answers from the bot against answers provided by ChatGPT, noticing that the bot's answers are much more helpful and precise.
Worth mentioning that the quality of the questions our early adopters bring to the bot is extremely high – thanks to the fact that these engineers are experts themselves, from companies like AWS, EDB, GitLab, Timescale.
Some people look much forward and raise interesting ideas. Just a couple of them:
- ability to create a patch for Postgres (we plan to add this – a "hacker toolset")
- desire to have a similar system for all major open source ecosystems (we don't plan it, at least for now).
Future plans
This post is already huge, so it wouldn't make sense to provide the long list of ideas and plans we have (it's growing like a snowball).
Instead, let me conclude with the idea that we see two big horizons that are going to define the development roadmap for the bot.
Testing
All kinds of testing, related to databases. Think automated pull request reviews from database perspective, highlighting all potential issues: risks of long exclusive locks for schema changes, forgotten indexes or LIMIT in queries, SELECT+1 pattern. The bot detects potential issues, tests them in efficient environments, demonstrates to developers, explains, proposes fixes.
Education
The best way to learn anything, including databases and SQL, is through practice. For databases and SQL, it means work with large datasets. This is solved by Postgres.AI DBLab Engine. With Postgres.AI bot, it will become possible to practice on large datasets, according to some plan and at convenient pace the user chooses. And if something is not clear, the bot would always explain.
Join!
- Join the alpha testing program: https://postgres.ai/bot
- Reach out to me if you have ideas for collaboration: [email protected]