How partial, covering, and multicolumn indexes may slow down UPDATEs in PostgreSQL

Based on a true story.
This article was originally published in 2018. This is a reviewed and extended version of it. The discussed findings can be applied to any actual major version of PostgreSQL.
Primum non nocere
"Primum non nocere" – this is a fundamental principle that is well-known to anyone working in healthcare: "first, do no harm". It is a reminder: when considering any action that is supposed to improve something, we always need to look at the global picture to see if there might be something else that be damaged by the same action.
This is a great principle and it is used not only in healthcare, of course. I strongly believe that it has to be used in database optimization too, and we need better tools to make it happen.
One day, a few years ago, when I already started to help Silicon Valley startups with Postgres performance optimization, I broke this rule. Postgres has a lot of features and it provides plenty of ways to optimize query performance, so it may be very tempting to start using some clever optimization right away. You have a query, you see a way to optimize, you collect the data showing how faster the query will be, you've got approval from the engineering team you help – what else do you need to deploy this optimization? What could possibly get wrong? If you are a database consultant or a DBA/DBRE with a few years of experience, I'm sure you were in these shoes.
"Primum non nocere" – this must be applied to query optimization too. If you found a great way to optimize a query, you should ask: "might this optimization make the performance of some other queries worse?". Well, in many cases the answer is "probably, yes", and if you know how to check it or – better! – have good tooling to answer this question holistically (we'll talk about it in the end), you're bringing your performance optimization and database change management to the next level.
Back to my old case, here is what happened. I found that some query was dealing with a relatively small fraction of rows in the table, but the query execution was based on some regular index. Postgres indexes come with a lot of various flavors: besides the type of the index you may choose, there are multicolumn, functional, partial, and – since Postgres 11 – covering indexes. For the SELECT queries, I was optimizing, using a partial index was a natural choice. It improved the SELECT indeed, as expected. But it also made UPDATEs to the same table significantly slower!
This was a big surprise. I know that this will be a surprise to many of my readers too. Let's buckle up and travel through a series of short experiments to explore how this may happen: we'll check various index options looking at the performance of both SELECT and UPDATE queries, and in the end, we'll try to draw some useful conclusions, as well as discuss how we can build an optimization approach that would follow the "first, do no harm" principle.
First, a few words about what partial and covering indexes are – feel free to scroll down to the "Experiments" if you know it.
DBLab Engine
Instant database branching with O(1) economics.
Partial indexes
Partial index is a good way to save some disk space and improve record lookup performance. The common rule is "use it when you can afford it" — in other words, if all your queries involve some filter, it is usually considered a good idea to include such filter to index definition, to reduce its size and improve its performance (the smaller your index is, the faster the corresponding index scan will be).
Here is an example from Postgres documentation on this topic:
create index orders_unbilled_index
on orders (order_nr)
where billed is not true;
– if the query we're optimizing includes the same filter on the billed column, this index will be considered by the query planner. And the filter targets quite a small part of the overall row volume in the table, we should see a significant performance improvement for the corresponding index scans.
Partial indexes are smaller, they target the rows we need – sounds like an obvious win (of course, if our queries have filters in the WHERE clauses matching the WHERE clauses in the partial index you're going to use). But as we'll soon see, switching to partial indexes can break the "Primum non nocere" principle.
Multicolumn and covering indexes. Index-only scans
Indexes are used not only to locate the data we need, but also read and use that data. This can be done via using either multicolumn or – since Postgres 11 – covering indexes. Covering indexes contain values from additional columns but these values are not used as keys in B-tree.
So the first option to include a value to the column is using a multicolumn index:
create index i_myindex
on table mytable
using btree(col1, col2);
The second was – a covering index:
create index i_myindex
on table mytable
using btree(col1)
include(col2);
If our SELECT involves only those columns which values are present in the index, we can rely on Index-only Scans – the may be a much faster alternative to Index scans, because dealing with the heap is not needed anymore. In this scenario, all we need is to tune autovacuum to keep our tables in a "good shape", to have as few interactions with the heap (table data) as possible. Franck Pachot explores it very well in his article "Boosts Secondary Index Queries with Index Only Scan".
I had always an impression that covering indexes are mostly useful in the case of UNIQUE index and unique constraint enforcement – if we have a unique index and want to add a column to it, we cannot just extend the list of columns because it would change the uniqueness constraint. Instead, we add it to INCLUDE. However, Franck showed to me another benefit of covering indexes compared to multicolumn ones – changing values of the "extra" column in a covering index is lighter (hence, faster) than the same change in the case when the column is a part of the column list in a multicolumn index (here is a simple demo from Franck).
Experiments
To explore various index options, we will use only what is available in any PostgreSQL database. I've documented the whole experiment series in a GitLab snippet: https://gitlab.com/-/snippets/2193918, so you can repeat the steps easily. In the same snippet you can also find the result of execution that I've got on the laptop used to write this post (Macbook Air, M1 2020). The numbers discussed further are those that I had on this hardware.
DB schema
Consider a simple example:
create table asset(
id bigserial primary key,
owner_id int8 not null,
created_at timestamptz default now(),
c1 int8,
c2 int8,
c3 int8,
price int8
);
Let’s assume that in this table we store information about some assets, and let’s fill it with some sample data:
insert into asset(
owner_id,
c1,
c2,
c3,
price
)
select
round(random() * 10000),
round(random() * 1000000), -- c1
round(random() * 1000000),
round(random() * 1000000),
round(random() * 10000000) -- price
from generate_series(1, 600000) i;
And let’s add more sample data, this time with "unknown" price:
insert into asset(
owner_id,
c1,
c2,
c3,
price
)
select
round(random() * 10000),
round(random() * 1000000), -- c1
round(random() * 1000000),
round(random() * 1000000),
null -- price is unknown (yet)
from generate_series(600001, 1000000) i;
create index on asset(c1);
create index on asset(c2);
create index on asset(c3);
Now we have 1 million records, 40% of them having yet-unknown (null) price.
As you can see, we created 3 indexes on int8 columns c1, c2, and c3 – let's assume that some useful data is stored in that columns. The presense of these indexes, as we'll see later, make regular UPDATEs more expensive – not a rare condition that is known as "write amplification".
Workload
We will use 3 types of queries.
Consider situation when we need to quickly find the sum of prices of all assets that belong to a specific owner:
select sum(price)
from asset
where owner_id = :owner_id;
Additionally, we'll check the following query too:
select sum(price)
from asset
where
owner_id = :owner_id
and price is not null;
Semantically, it is equivalent to the previous query because sum(..) doesn't take into account NULL values. However, as we will see, the original query cannot use a partial index with where price is not null. Theoretically, PostgreSQL planner could have a proper optimization for such case, but currently it doesn't have it.
Finally, UPDATEs. Prices change from time to time, so any record might be UPDATEd to have a new, corrected price value. We will use the following query as an example (excuse it for being quite pessimistic, making prices only grow all the time):
update asset
set price = price + 10
where id = :id;
We are going to use the standard PostgreSQL benchmarking tool pgbench to generate workload – we will create 3 files with custom single-query transaction and specify proper number of clients/jobs suitable (I used -j4 -c12 in my case):
echo "=== ### Benchmark scripts ==="
echo "\\set owner_id random(1, 1000)" > selects.bench
echo "select sum(price) from asset where owner_id = :owner_id;" >> selects.bench
echo "\\set owner_id random(1, 1000)" > selects_not_null.bench
echo "select sum(price) from asset where owner_id = :owner_id and price is not null;" >> selects_not_null.bench
echo "\\set id random(1, 600000)" > updates.bench
echo "update asset set price = price + 10 where id = :id;" >> updates.bench
for test in selects selects_not_null updates; do
pgbench test --no-vacuum \
--report-latencies --time=30 --progress=10 \
--jobs=4 --client=12 \
--protocol=prepared \
--file="${test}.bench"
done
Indexes
What index do we need to use to make our queries fast? Here are some ideas that should naturally come to a DBA's mind:
- The UPDATE should be fast already – we should have a lookup using the primary key there because we need to find a row with specific
idvalue. So we should think about optimizing the SELECT queries only. - To be able to find all records belonging to some owner (filter
where owner_id = :owner_id) efficiently, we need to have an index on theowner_idcolumn. - If we consider the SELECT query with additional filter
... and price is not null), then it is reasonable to assume that making the index partial should improve the index scan speed:create index ... where price is not null. Worth checking it. - To avoid dealing with heap, we can include
pricevalues into the index itself. There are two ways to do it: either make the index multicolumn ((owner_id, price)) or start using a covering index (keywordINCLUDEin the index definition). Convering indexes were introduced in PostgreSQL 11. Regardless of the method we choose, with bothowner_idandpricevalues presented in the index, Postgres can extract those values from the index itself and dealing with heap (table data) is not needed anymore. In the best case, it won't touch the heap at all performing an Index-only scan – it will happen if all pages are marked visible. Otherwise, Postgres needs to check the proper entries in the heap – it is reported asHeap Fetches: XXin the output ofexplain (analyze, buffers)for the query. To keep the number of Heap fetches low (therefore, the Index-only scan really fast), one might need to tune autovacuum to encourage it to process the table more frequently and take measures to prevent big lags of so-called "xmin horizon" – however, this question is outside of the scope of this article.
With these considerations in mind, we are ready to have the list of the indexes for our benchmark series:
- No additional indexes – let's check this too, just for the sake of completeness.
- 1-column index:
create index i_1column
on asset
using btree(owner_id); - Multicolumn index:
create index i_2columns
on asset
using btree(owner_id, price); - Partial index:
create index i_partial
on asset
using btree(owner_id)
where price is not null; - Covering index:
create index i_covering
on asset
using btree(owner_id)
include (price); - Finally, partial covering index:
create index i_partial_covering
on asset
using btree(owner_id)
include (price)
where price is not null;
What we look at
First of all, we are interested in how all three queries behave – pgbench provides latency and TPS numbers. In these experiments, we are aiming to get as much as possible from the resources we have, so our primary metric will be TPS achieved.
Next, we are interested in seeing what plans the Postgres planner choses for all of three queries in each case: we'll use simple explain <query>; – without actual execution because we're interested only in structure. Note that the plan chosen can vary depending on the value used – we'll use 1 both for id in the UPDATE query and for owner_id in the SELECT queries, assuming that the plan will be the same for all other values because they should be evenly distributed, in our very synthetic case.
Finally, we are interested to know the size of the indexes are how it changes after our 30-second UPDATE workload. To do so, we'll use this simple command in psql, two times – before and after UPDATEs:
\di+ i_*
Oh, and one more thing – the most important one! We'll check how many of the UPDATEs were "HOT":
select
n_tup_upd,
n_tup_hot_upd,
round(100 * n_tup_hot_upd::numeric / n_tup_upd, 2) as hot_ratio
from pg_stat_user_tables
where relname = 'asset';
"HOT" stands for Heap Only Tuples, this is an internal technique of how PostgreSQL may perform an UPDATE of a tuple. It's not well documented in the main PostgreSQL documentation, but here is a few tips helpful for those who are interested to learn about it:
- check out the Postgres source code: README.HOT explain details in plain English very well,
- read the article by Laurenz Albe: "HOT updates in PostgreSQL for better performance" (2020),
- dive into the implementation details with Hironobu Suzuki: the chapter 7 "Heap Only Tuple and Index-Only Scans" of his "The Internals of PostgreSQL" series is very deep,
- learn from Egor Rogov: "MVCC in PostgreSQL-5. In-page vacuum and HOT updates" (2020), it's the 5th part of his series of articles related to Postgres MVCC.
As already mentioned, the GitLab snippet has all the details in the form of shell script (can be run uzing bash or zsh). It also includes the step to collect the data we need.
Results
The raw results I had on my hardware can be found in the same GitLab snippet. Here is the summary:
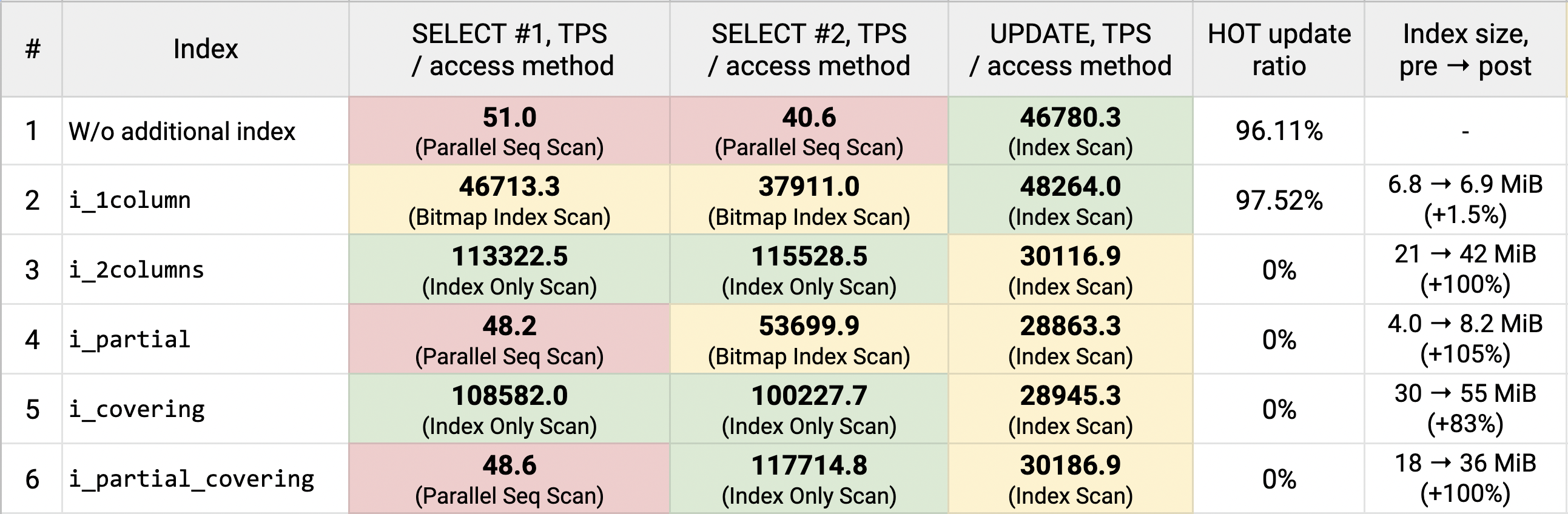
What index version would you choose for the queries we analyze? Looking at this picture, I'd probably stay with the 1-column index. It demonstrates quite good performance for the SELECT queries (not excellent, thought), it is very fast for the UPDATEs, and its size doesn't grow under them – the index doesn't get bloat under these UPDATEs.
Of course, for different kinds of queries and data, the picture could be different. And in some circumstances, I might want to choose the covering or 2-column index – this could happen if I needed better SELECT speed and cared about UPDATEs less.
Lessons learned
- The key lesson: if we include a column in an index definition UPDATEs changing values in that column cannot be HOT anymore, and this may make UPDATEs significantly slower. Most (~97%) of the UPDATEs changing
pricewere HOT for the case with 1-column index onowner_idand, of course, for the case without an additional index defined. But oncepricebecomes a part of the index definition, all updates lose their "HOTness". And this is very noticeable: the TPS value drops from ~48k to ~28-30k – so we have ~40% degradation. The level of degradation depends on how big is the difference between HOT and regular UPDATEs: the more indexes we have on the table, the bigger this difference can be. - One might easily expect this effect to happen (though it's still easy to forget about it) when using a column in multicolumn or covering indexes. But partial indexes demonstrate this behavior too and this may be very surprising. If we put a column definition to the
WHEREclause ofCREATE INDEX- UPDATEs changing values in that column cannot be HOT anymore, therefore they become slower. Optimizing SELECTs using a partial index and not checking the behavior of the UPDATE queries, we would definitely break the "Primum non nocere" rule. - It is well-known that any new index created slightly slows down write operations (UPDATEs, DELETEs, INSERTs) – but that degradation is usually much smaller than that one we observed here (in fact, without any additional index, we had even slightly lower TPS for the UPDATE queries than for the case with 1-column index: 46k vs. 48k).
- The covering index turned out to be significantly bigger than the 2-column one: 30 MiB vs. 21 MiB. This is because btree deduplication added in Postgres 13 is not implemented for covering indexes (for Postgres 11, the index size will be the same).
You might have additional interesting thoughts. I would love to hear them! Ping me in Twitter to discuss it: @samokhvalov.
Holistic approach: performance regression testing in CI/CD pipelines
How would we avoid similar problems when making database changes? We live in the era of very advanced CI/CD tools and methodologies, so a reasonable answer here would be "let's have some set of tests that will help us detect and prevent performance degradation".
This may sound complicated, but the good news is that we already have all the building blocks to build required for this. The core block here is Database Lab Engine (DLE) – a tool that provides instant thin clones of PostgreSQL databases. Cloning speed does not depend on the size of the database, and on a single machine with a single storage volume, we can run dozens of clones simultaneously.
Fast and cheap cloning is essential – it allows you to have automated testing based on large data volumes right in CI/CD pipelines. If DLE is properly tuned, it will provide query plans that are identical to production – and due to how the PostgreSQL planner is working, this becomes possible even if DLE is running on a weaker machine compared to production.
Then, to have reliable regression testing of query performance, we need to define the set of queries that are critical to business and define parameters for them (parameters are important – for the same query, Postgres planner may choose different plans for different parameters used). This procedure is not yet fully automated; it requires some effort for initial setup and further maintenance. However, once properly done, we have a workflow in which any change is automatically tested to check if the change will affect some critical query's performance.
For example, for the idea to switch from the 1-column index to a partial one demonstrated in this article, the performance regression testing tool would suggest that the UPDATE queries are going to get significant performance degradation if we deploy the change – so the engineers responsible for the change review now see the risks and have good data to make the decision on the change approval.
Primum non nocere. First, do no harm.

DBLab Engine
Instant database branching with O(1) economics.