DBLab 4.0: instant database branching with O(1) economics


The cost of experimentation determines the pace of innovation. In database development, this cost has traditionally been measured in hours and thousands of dollars per environment. DBLab Engine 4.0 changes this equation fundamentally with instant database branching.
New version delivers comprehensive database branching for Postgres with unique set of characteristics:
- Git-like semantics: branches are named pointers to snapshots
- O(1) scaling for both storage and compute costs
- True open source (Apache 2.0 license)
In test environments, we now face three distinct workload types demanding fast and inexpensive full-scale database provisioning:
- Human developers - ad hoc experimentation, query optimization, feature development
- CI/CD pipelines - gets every change tested before production (e.g., schema changes), achieving 100% coverage for database changes
- AI agents - massive parallel experimentation, trying hundreds to thousands of approaches
The third category is new and growing explosively. AI agents don't just need one or two test environments - they need hundreds, thousands or experimental databases, created and destroyed in rapid succession. Traditional database management makes this prohibitively expensive. DBLab 4.0 makes it effectively free – same cost whether you run 1 experiment or 1,000.
Key concepts
Before diving into the new features, here's how DBLab's terminology maps to practical usage:
- Snapshot - static (read-only) state of database
- Clone - endpoint, PostgreSQL server, writable
- Branch - named pointer to snapshot (Git concept)
What's new in 4.0
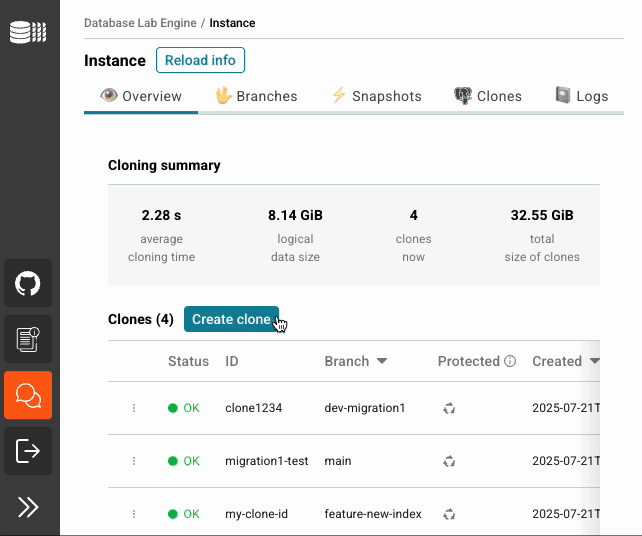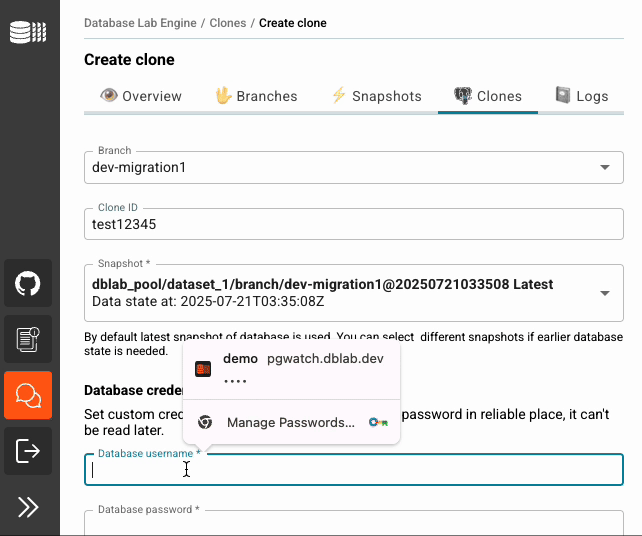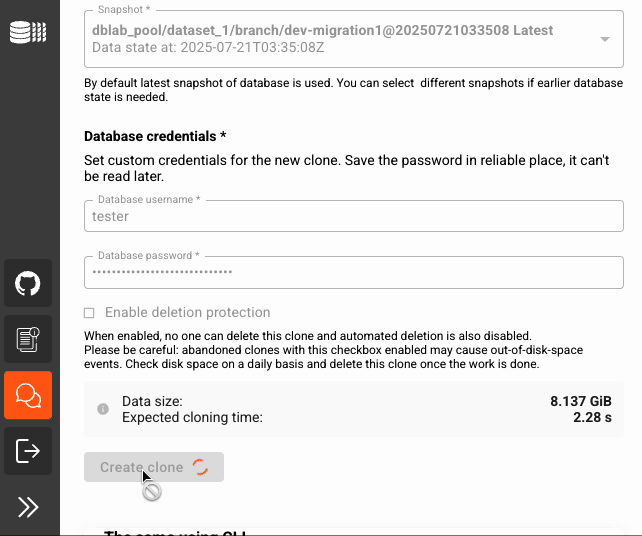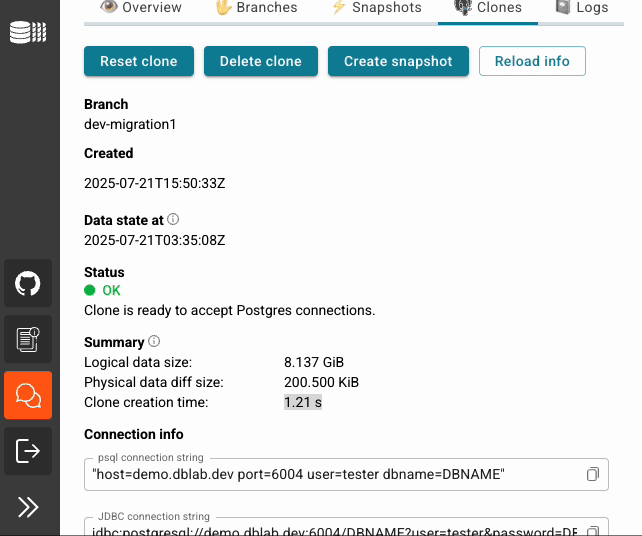
1. Snapshots on demand
While DBLab has always created snapshots automatically, v4.0 gives control to users:
# Create a clone to work with
dblab clone create --branch main --id my-clone-id --username postgres --password <your-password>
# Connect to your clone and make some changes
psql -h localhost -p 6001 -U postgres # port may be different
...
# Create a snapshot from your clone to save your work
dblab commit --message "Added new indexes" --clone-id my-clone-id
# Now, you can destroy your clone to free up resources
dblab clone destroy --clone-id my-clone-id
# You or your team can return to that state by creating a new clone from the snapshot
dblab clone create --snapshot-id <snapshot-id> --id my-clone-id --username postgres --password <your-password>
Why it matters: This enables true experiment-centric development. Test risky changes in an isolated clone, save successful state in snapshots, and share work with your team. You're allowed to fail → allowed to learn, with instant ability to spawn new clones from any snapshot.
And what's most important, multiple humans, CI pipelines, and AI agents can now test the result of your work independently.
2. Instant database branching
DBLab 4.0 introduces true database branches - named pointers to snapshots that you can create, switch, and manage just like Git branches. Here's how it looks like:
PGDATA (1 TiB) ━━━━●━━━━━━━━━━━━━━━━━●━━━━━━━━━━━━━━━● ← main branch
│ │
└──● snapshot1.1 └──● snapshot2.1 ← experiment-branch
│
└──────● snapshot1.2 ← feature-branch
Example workflow:
# Create a new dev branch based on this snapshot
dblab branch --snapshot-id <snapshot-id> dev-migration1
# Create a clone to test migrations
dblab clone create --branch dev-migration --id migration-test --username postgres --password <your-password>
# Create a snapshot before making changes
dblab commit --clone-id migration-test --message "before migration"
# Run your migration
psql -h localhost -p 6001 -f migration.sql
# Migration successful? Create a new snapshot
dblab commit --clone-id migration-test --message "after migration"
# Something went wrong? Reset clone to previous snapshot
dblab clone reset --snapshot-id <snapshot-id>
Why it matters: This makes database work close to what we already have in Git. For example, we can have a DBLab branch for each Git branch, and collaborate effectively.
3. Webhooks for automation
Integrate DBLab into your workflows with webhooks for major events. Add this to your configuration:
webhooks:
hooks:
- url: "https://monitoring.example.com/webhook/dblab"
secret: "webhook-secret-token"
trigger:
- clone_create
- clone_reset
- url: "https://ci.example.com/api/v1/database-ready"
trigger:
- clone_create
Why it matters: This enables sophisticated CI/CD pipelines and ChatOps workflows, making database experimentation a first-class citizen in your development process. For instance, you can automate creation of REST API layer (think PostgREST, Supabase) for each clone.
4. macOS support
DBLab Engine 4.0 now runs on macOS using Colima, a lightweight Linux VM. ZFS modules are installed inside the VM, giving you full database branching capabilities on macOS. Perfect for offline development, secure environments, or when you need local database experimentation without cloud dependencies.
See the macOS setup guide for detailed instructions.
Why it matters: Database development anywhere - on airplanes, in secure facilities, or offline.
5. Full refresh on demand
For logical mode, users can now initiate full refresh using API, CLI, or UI. This was one of the most requested features among DBLab 3.5 users, addressing the need for manual control over data synchronization when automatic refresh isn't sufficient.
# Trigger full refresh via CLI
dblab instance full-refresh
Why it matters: Gives teams complete control over when and how their data gets updated, ensuring they always work with the most relevant data for their specific testing scenarios.
The O(1) revolution
Traditional database cloning scales linearly - double the developers, double the costs. DBLab changes the equation:
Traditional approach - O(N):
- 10 developers need 10 database copies
- 1 TiB of data becomes 10 TiB of storage
- $8,477.6/month in cloud costs (10 × RDS db.r7i.2xlarge + storage)
- Hours of waiting multiplied by frustration
DBLab approach - O(1):
- 10 developers share one DBLab instance
- 1 TiB of data remains ~1 TiB (plus small deltas)
- ~$800/month total (fixed price regardless of clone count)
- 2 seconds per clone, always
This changes how teams work with databases - every developer gets their own full-scale environment without the cost penalty.
How different database cloning approaches scale
| Approach | Time to provision N clones | Compute costs | Storage costs |
|---|---|---|---|
| Traditional (thick) cloning | O(N) | O(N) | O(N) |
| EC2 + EBS volumes from snapshots | O(N) | O(N) | O(N) |
| RDS clones | O(N) | O(N) | O(N) |
| Aurora thin clones; Neon | O(1) | O(N) | O(1) |
| DBLab thin clones | O(1) | O(1) | O(1) |
DBLab is the only solution that achieves O(1) scaling across all three dimensions - provisioning time, compute costs, and storage costs.
This comparison assumes developers do not limit themselves in experimentation with full-size databases, including true testing in CI and AI-driven workflows for development and testing.
Real-world cost example: 10 developers, 1 TiB database
| Solution type | Approach | Provisioning time | Storage cost | Compute cost | Total |
|---|---|---|---|---|---|
| RDS thick clones | Full copies (traditional) | hours (with warming up because of lazy load) | 1 TiB × 10 developers × $117.76 = $1,177.6 | 10 × db.r7i.2xlarge × $730 = $7,300 | $8,477.6 |
| RDS Aurora thin clones | Aurora CoW storage, separate compute | minutes | ~1 TiB × $102.4 = $102.4 (plus IO costs) | 10 × db.r7i.2xlarge × $846.8 = $8,468 | $8,570.4 (plus IO costs) |
| DBLab branching | CoW storage + shared compute | ~1 second | ~1 TiB × $81.92 = $81.92 | 1 × r7i.2xlarge × $386 + DBLab SE $331 = $717 | $798,92 |
The difference is stark: DBLab costs 90% less than traditional solutions. Plus, 2-second provisioning vs minutes or hours changes how developers work entirely.
Pricing based on AWS pricing as of 2025: RDS Postgres db.r7i.2xlarge at $730/month, RDS Aurora for Postgres db.r7i.2xlarge (8 vCPU, 647 GiB RAM) at ~$426/month, DBLab SE on r7i.2xlarge at $717/month, EBS gp3 storage at $0.08/GiB/month (1 TiB = $81.92/month), general purpose SSD (gp2) at $0.115/GiB/month (1 TiB = $117.76/month).
Why instant matters: the experimentation bottleneck
Consider a typical development scenario: testing a complex migration on production-scale data. With traditional approaches:
- Wait 2-4 hours for thick clone provisioning
- Pay $730+ for that single test environment (RDS)
- Think twice before trying alternative approaches
- Share environments between developers to control costs
This friction kills experimentation. Developers take fewer risks, test less thoroughly, and ship more conservatively.
The 2-second branching changes everything. Consider how teams work today:
Without instant branching:
- Wait hours for test environments
- Share staging databases to save costs
- Test directly on production (!)
- Delay experiments until "worth the wait"
With instant DBLab branching:
- Every developer gets their own branch for every feature
- QA can spin up isolated environments for each test scenario
- CI/CD pipelines can test migrations on full-scale data
- AI agents can explore hundreds of optimization paths in parallel
When creating a branch or a clone takes a second and costs nothing extra, teams actually use them. The cost of experimentation drops to zero.
Performance at scale
Testing with production workloads demonstrates:
- Clone creation: <2 seconds for any database, regardless of size (even if it's 50 TiB!)
- Snapshot creation: O(1) operation regardless of database size
- Branch switching: Instant (pointer update only)
- Concurrent users: 15 users on 10 TiB database with 30-second clone creation under load
Open source foundation
We're releasing DBLab Engine 4.0 under Apache 2.0, so teams can:
- Deploy on any infrastructure
- Customize for specific needs
- Avoid vendor lock-in
- Contribute improvements back to the community
Commercial support is available through:
- DBLab SE (Standard Edition): Adds commercial support, monitoring, and compatibility images for managed PostgreSQL services (RDS, Aurora, CloudSQL, Heroku, Supabase, Timescale Cloud)
- DBLab EE (Enterprise Edition): Full platform with user management, audit with SIEM, SSO, and enterprise features
Future work
We're working on:
1. Support logical replication:
Continuously updated state in "logical" mode, like already implemented for "physical" mode. One disk (dataset) would be enough to have multiple snapshots.
2. ZFS send/recv for instance synchronization:
Support sync between DBLab instances, including sync from staging DBLab to local DBLab installed on laptops.
3. Major upgrade as a feature:
Support testing new Postgres versions in DBLab.
Where to start
- Try the demo: demo.dblab.dev (token:
demo-token) - Deploy DBLab SE: AWS Marketplace or Postgres AI Console
- Install open source: How-to
- Enterprise inquiries: Contact [email protected] for DBLab EE
DBLab 4.0 represents our vision of experiment-centric Postgres management fully realized. By making database environments as fluid and manageable as code, we're enabling teams to move faster while reducing risk.
Get Started | GitLab | Join our Slack
Bogdan Tsechoev
Software Engineer at PostgresAI
DBLab Engine
Instant database branching with O(1) economics.