PostgreSQL subtransactions considered harmful

An opinionated overview of four cases against using PostgreSQL subtransactions
💬 Hacker News discussion
💬 "Why we spent the last month eliminating PostgreSQL subtransactions" (GitLab)
This article discusses what subtransactions are, how to create them, and how widely they are used nowadays. Next, we try to understand why they have a terrible reputation among PostgreSQL experts who operate heavily loaded systems. We overview four problems that may arise in a Postgres database in which subtransactions are used, and load grows. In the end, we discuss the short-term and long-term options for PostgreSQL users willing to solve the ongoing or prevent future problems related to subtransactions.
What is a subtransaction?
Subtransaction, also known as "nested transaction", is a transaction started by instruction within the scope of an already started transaction (definition from Wikipedia). This feature allows users to partially rollback a transaction, which is helpful in many cases: fewer steps need to be repeated to retry the action if some error occurs.
The SQL standard defines two basic instructions describing this mechanism: SAVEPOINT and extension to the ROLLBACK statement – ROLLBACK TO SAVEPOINT:
<savepoint statement> ::=
SAVEPOINT <savepoint specifier>
<savepoint specifier> ::=
<savepoint name>
<rollback statement> ::=
ROLLBACK [ WORK ] [ AND [ NO ] CHAIN ] [ <savepoint clause> ]
<savepoint clause> ::=
TO SAVEPOINT <savepoint specifier>
It also defines RELEASE SAVEPOINT that allows erasing information about an "active" savepoint:
<release savepoint statement> ::=
RELEASE SAVEPOINT <savepoint specifier>
PostgreSQL supports nested transactions since version 8.0 (see commit 573a71a made on June 30, 2004). It supports a slightly different syntax compared to the SQL standard – for example, allowing to omit the word SAVEPOINT in the RELEASE and ROLLBACK statements:
SAVEPOINT savepoint_name(doc)ROLLBACK [ WORK | TRANSACTION ] TO [ SAVEPOINT ] savepoint_name(doc)RELEASE [ SAVEPOINT ] savepoint_name(doc)
Here is a simple demonstration:
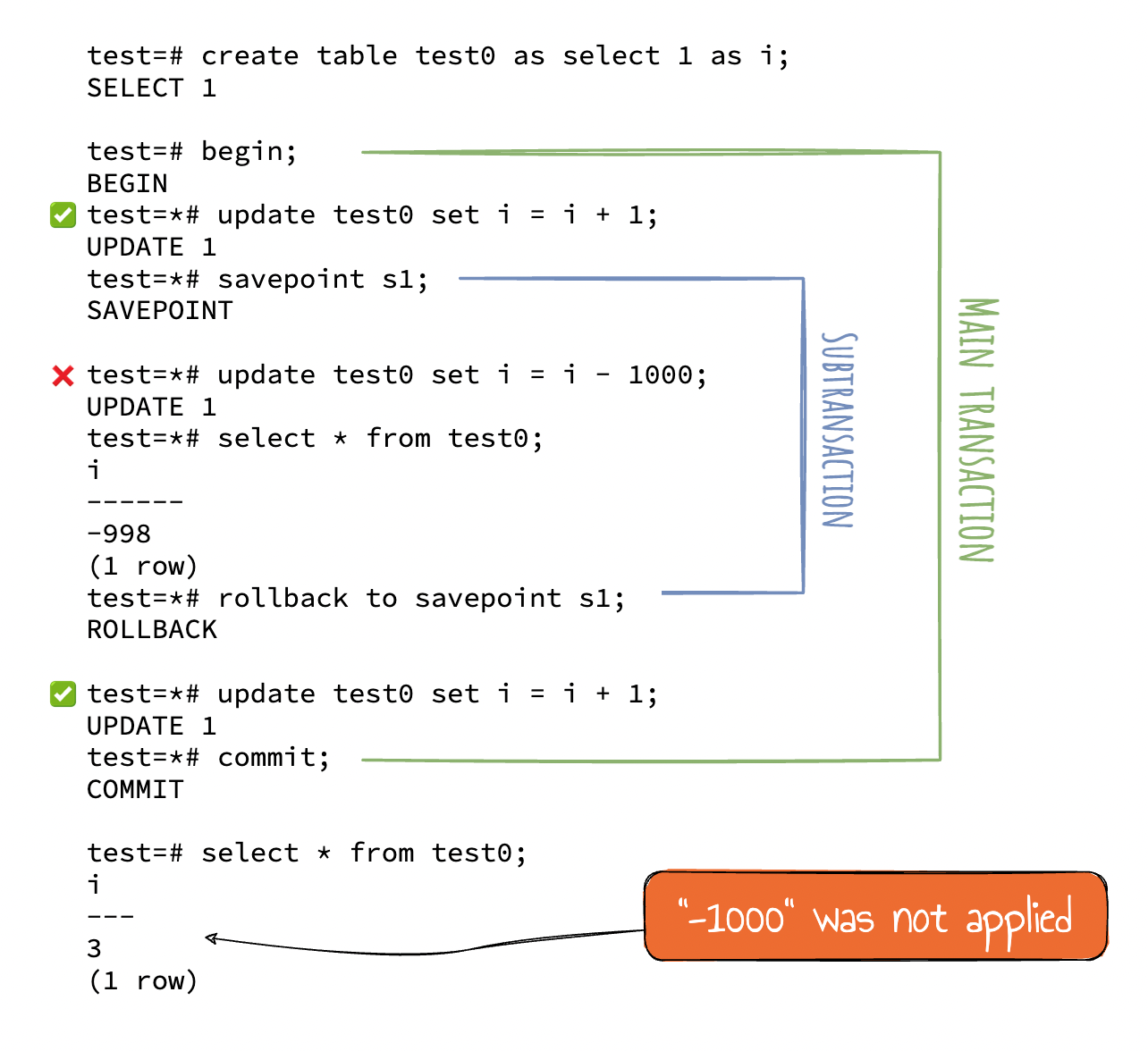
Who is using subtransactions?
Maybe, you are.
Today, the majority of the popular ORMs and frameworks support nested transactions natively. Some examples:
- Django
- SQLAlchemy
- Ruby on Rails / Active Record
- Sequel
- Spring Framework
- JOOQ
- Yii 2.0
- GORM
- Sequelize (sometimes, in a weird form)
Besides SAVEPOINTs, there are other ways to create subtransactions:
BEGIN / EXCEPTION WHEN .. / ENDblocks in PL/pgSQL code (the official documentation does not describe it well; explored, for example, in this article: "PL/PgSQL Exception and XIDs")plpy.subtransaction()in PL/Python code
One may assume that many applications that use PL/pgSQL or PL/Python functions use subtransactions. Systems that run API built on PostgREST, Supabase, Hasura might have PL/pgSQL functions (including trigger functions) that involve BEGIN / EXCEPTION WHEN .. / END blocks; in such cases, those systems use subtransactions.
Problem 1: XID growth
One of the basic issues with subtransactions is that they increment XID – the global transaction ID. As with regular transactions, this happens only if there is some modifying work – but if there are multiple nested subtransactions, all of them get their own XID assigned, even if a single modification happened inside the inneter-most of them.
Let's see, in a database where no activity is happening:
test=# create table test1(i int8);
CREATE TABLE
test=# begin;
BEGIN
test=*# select pg_current_xact_id(); -- use txid_current() in Postgres 12 or older
pg_current_xact_id
--------------------
1549100656
(1 row)
test=*# insert into test1 select 1;
INSERT 0 1
test=*# savepoint s1;
SAVEPOINT
test=*# insert into test1 select 2;
INSERT 0 1
test=*# savepoint s2;
SAVEPOINT
test=*# savepoint s3;
SAVEPOINT
test=*# insert into test1 select 3;
INSERT 0 1
test=*# commit;
COMMIT
test=# select pg_current_xact_id();
pg_current_xact_id
--------------------
1549100660
(1 row)
test=# select ctid, xmin, xmax, i from test1;
ctid | xmin | xmax | i
-------+------------+------+---
(0,1) | 1549100656 | 0 | 1
(0,2) | 1549100657 | 0 | 2
(0,3) | 1549100659 | 0 | 3
(3 rows)
In this example, the main transaction had XID = 1549100656, and additional XIDs – 1549100657, 1549100658, 1549100659 – were assigned to subtransactions defined by SAVEPOINTs s1, s2, and s3 respectively. As a result, the tuples in the table have different xmin values (to learn more about xmin, see "5.5 System Columns"), although they all were inserted in a single transaction. Notice that XID 1549100658 was not used in xmin values – no tuples were created between savepoint s2; and savepoint s3;. Overall, four XIDs were consumed instead of a single one as if could be in the case of a subtransaction-free transaction.
This example clearly shows two facts that may be not intuitive:
- XIDs assigned to subtransactions are used in tuple headers, hence participating in MVCC tuple visibility checks – although results of subtransactions are never visible to other transactions until the main transaction is committed (in PostgreSQL, "minimal" isolation level supported is
READ COMMITTED). - Subtransactions contribute to the growth of global XID value (32 bit, requiring special automated maintenance usually done by autovacuum). Therefore it implicitly increases risks associated with XID wraparound: if the mentioned maintenance is lagging for some reason and this issue is not resolved, the system may reach a point when the mechanism of transaction ID wraparound protection puts the cluster to the single-user mode causing long-lasting downtime (see examples of how popular SaaS systems were down because of that: Sentry, Mailchimp). One may have, say, 1000 writing transactions per second, but if they all use 10 subtransactions, then XID is incremented by 10000 per second. This might not be expected by users – poor autovacuum needs to run in the "transaction ID wraparound prevention" mode more often than it would be if subtransactions had "local" IDs inside each transaction, not "wasting" global XIDs.
Bottom line: there is a trade-off between active use of subtransactions and the XID growth. Understanding this "price" of using subtransactions is essential to avoid issues in heavily-loaded systems.
Problem 2: per-session cache overflow
The details for this problem are easy to find when one starts diving into the performance of Postgres subtransactions, uses Google, and ends up reading Cybertec's blog post related to PostgreSQL subtransactions performance.
There is a per-session threshold for the number of active subtransactions per session, exceeding which introduces an additional performance penalty: PGPROC_MAX_CACHED_SUBXIDS, which is 64 by default and can be changed only in Postgres source code:
/*
* Each backend advertises up to PGPROC_MAX_CACHED_SUBXIDS TransactionIds
* for non-aborted subtransactions of its current top transaction. These
* have to be treated as running XIDs by other backends.
*
* We also keep track of whether the cache overflowed (ie, the transaction has
* generated at least one subtransaction that didn't fit in the cache).
* If none of the caches have overflowed, we can assume that an XID that's not
* listed anywhere in the PGPROC array is not a running transaction. Else we
* have to look at pg_subtrans.
*/
#define PGPROC_MAX_CACHED_SUBXIDS 64 /* XXX guessed-at value */
This problem is covered well by Laurenz Albe from Cybertec in his blog post "PostgreSQL Subtransactions and performance".
We reproduced those benchmarks in this GitLab issue, documenting them in detail: https://gitlab.com/postgres-ai/postgresql-consulting/tests-and-benchmarks/-/issues/20. Anyone can do the same on any machine with any PostgreSQL version and measure the level of "penalty" when exceeding the threshold.
In the same GitLab issue, you can find the following additional information:
-
Adjusted benchmarks to have an "apples vs. apples" comparison – instead of removing the
SAVEPOINTcommand, we replace them with trivialSELECTones. This is done to avoid reducing the number of statements in transactions, so the number of RTTs is stable. This helps us ensure that low numbers of subtransactions do not add significant overhead – even if we use, say, 50 of them. Nevertheless, the performance does drop when we exceed thePGPROC_MAX_CACHED_SUBXIDSthreshold: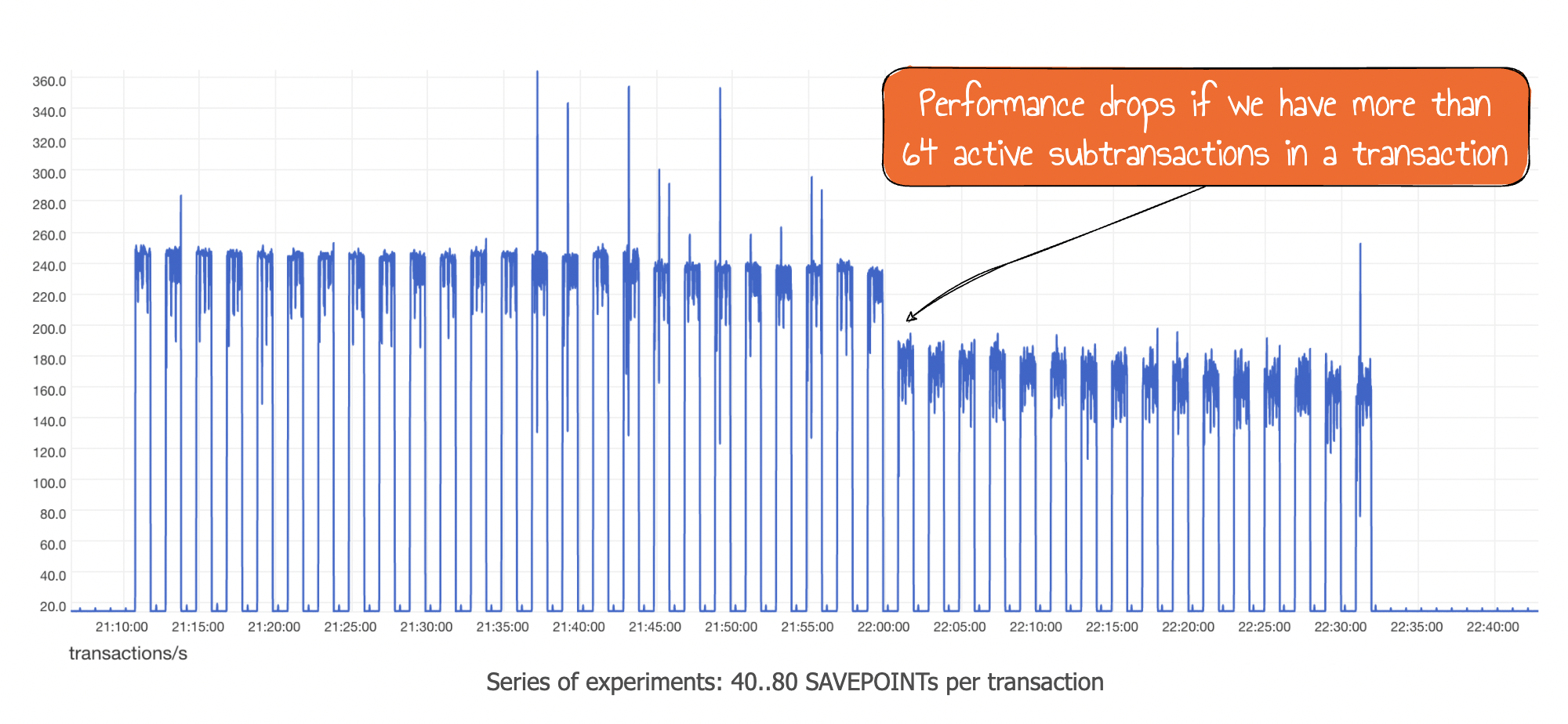
-
What happens if we run
RELEASE SAVEPOINTstatements to maintain the number of active subtransactions belowPGPROC_MAX_CACHED_SUBXIDS? Result: no degradation happens when passing the threshold defined byPGPROC_MAX_CACHED_SUBXIDS, even if we created overall 100 subtransactions in each transaction.
Verdict: when using subtransactions, avoid having more than PGPROC_MAX_CACHED_SUBXIDS (64 by default) active subtransactions in a session. It should be a rare situation, but it is still worth being careful. ORM users may want to implement logging or monitoring events for cases when subtransaction nesting depth is too large.
Problem 3: unexpected use of Multixact IDs
Nelson Elhage researches this problem in "Notes on some PostgreSQL implementation details". The article is excellent, highly recommended for reading. Worth noting, this article is quite tricky to find when you "google" Postgres subtransaction performance, and the case is quite exotic, but it's still worth including in our collection.
Here we will overview the problem briefly, citing the author.
Those readers who have used SELECT .. FOR SHARE in heavily loaded systems probably know about the performance risks it introduces. Multiple transactions can lock the same row, engaging the so-called Multixact ID and MultiXact store. Being convenient and helpful, this mechanism, when used at a large scale, can be prone to terrible performance issues:
One fun fact about the MultiXact store is that entries are immutable; if a new transaction locks a row that is already locked, a new MultiXact ID must be created, containing all the old transaction IDs as well as the new ID. This means that having N processes locking a row concurrently requires potentially quadratic work, since the list of transaction IDs must be copied in full, each time! This behavior is usually fine, since it's rare to have many transactions locking the same row at once, but already suggests that SELECT FOR SHARE has some potentially-disastrous performance cliffs.
Experienced engineers know about this problem and try to avoid using SELECT .. FOR SHARE under heavy loads. There is another mechanism, SELECT .. FOR UPDATE, which, of course, has some overhead: locking the tuples is dirtying the corresponding pages immediately. However, it is extremely useful when one needs to process a lot of records in multiple sessions – it helps avoid conflicts, so high throughput of processing is achieved. The straightforward overhead is a price worth paying - at the end of the day, the result of the processing is DELETEs or UPDATEs applied to the locked rows, so tuples are supposed to be dirtied.
But the situation becomes much, much worse if you combine SELECT .. FOR UPDATE and subtransactions:
Under load, we saw our query latency to our Postgres database spiking precipitously, and our throughput plummeting virtually to 0; the database would almost completely lock up and make virtually no progress at all for a while. During these lockups, we would dig into
pg_stat_activityand other tools, and see a large number of queries blocked on a number of apparently-relatedwait_event/wait_event_typepairs:
LWLock:MultiXactMemberControlLockLWLock:MultiXactOffsetControlLockLWLock:multixact_memberLwLock:multixact_offset
Then the author describes the synthetic pathological workload that triggers the performance issues, mentioning that it took significant effort to determine it:
SELECT [some row] FOR UPDATE;
SAVEPOINT save;
UPDATE [the same row];
In their case, they were using Django; it uses subtransactions by default, so the solution was to disable them entirely:
We changed the inner
transaction.atomicto passsavepoint=False, which turns it into a no-op if already inside an open transaction, and our problems immediately disappeared.
Finally, the author mentions the opinion from a friend with strong Postgres expertise:
Subtransactions are basically cursed. Rip em out.
Result: be extremely careful with SELECT .. FOR UPDATE in transactions that include subtransactions.
Problem 4: Subtrans SLRU overflow
This problem needs to be described in a little bit more detailed form because, as I believe, a growing number of systems might experience it. It was recently observed in a heavily-loaded system one of our clients is running (I hope they will share their experience soon in a separate blog post; UPDATE: here it is – "Why we spent the last month eliminating PostgreSQL subtransactions" (GitLab)).
The key aspects in this case are:
- On the primary:
- Subtransactions are used (even rare use of them is enough), issuing UPDATEs to some records (DELETEs may be a problem too, though this needs double-checking)
- There is an ongoing long-running transaction; the exact meaning of "long" here depends on the XID growth in the system: say, if you have 1k TPS incrementing XID, the problem might occur after dozens of seconds, so "long" = "dozens of seconds long", and if you have 10k TPS, "long" might mean just "a few seconds long". So in some systems, just a regular slow query may become such an offending transaction
- On standbys: SELECTs dealing with the same tuples there were changed by those recent transactions with subtransactions
The problem was analyzed and reproduced in this GitLab issue: https://gitlab.com/postgres-ai/postgresql-consulting/tests-and-benchmarks/-/issues/21. Here I provide a brief summary for those who don't have time to read through all the attempts presented in the GitLab issue.
To reproduce the problem, we need at least two PostgreSQL servers working as primary and hot standby. We use two EC2 instances of type c5a.4xlarge (32 GiB, 16 vCPU) with Ubuntu 20.04 and PostgreSQL 14beta3 installed using a forked and adjusted postgresql_cluster (a handy tool, developed and maintained by Vitaliy Kukharik, to automate the installation of PostgreSQL with various additional components such as Patroni). To observe the performance issues from various angles, we used perf, pgCenter by Alexey Lesovsky, pg_wait_sampling by PostgresPro (its package is available in the official PGDG Apt repository), and an excellent monitoring tool Netdata that allows exporting the monitoring dashboard so anyone can explore all the details of the experiments later.
The database for tests was a standard pgbench-generated database with scale factor 1 (-s 1).
On the primary, I run two types of workload:
-
a constant stream of transactions that include 3 SAVEPOINTs and a single UPDATE of one of 10,000 rows, executed using pgbench and a custom workload file:
echo "\\set id random(1, 10000)
begin;
savepoint s1;
savepoint s2;
savepoint s3;
update pgbench_accounts set aid = aid where aid = :id;
commit;" > updates_with_savepoints.sql
pgbench -rn -P2 -T3600 -c15 -j15 \
-f updates_with_savepoints.sql \
-M prepared \
test -U postgres \
2>&1 | ts | tee -a updates_with_savepoints.log -
in a separate psql session, 5-minute transactions not doing anything except obtaining the next XID, with 5-minute breaks after it:
select txid_current(), pg_sleep_for('5 minutes') \watch 300
On the standby, I used pgbench, selecting one of 10,000 rows (same that are being UPDATEd on the primary):
echo "\\set id random(1, 10000)
select * from pgbench_accounts where aid = :id;" > selects.sql
pgbench -rn -P2 -T36000 -c15 -j15 \
-f selects.sql \
-M prepared \
test -U postgres \
2>&1 | ts | tee -a selects.log
Furthermore, besides the Netdata monitoring, the following snippets used on the standby helped us observe the problem in real-time:
- Wait event profiling in Postgres, using pg_wait_sampling:
echo 'select pg_wait_sampling_reset_profile(); select event, sum(count) from pg_wait_sampling_profile group by 1 order by 2 desc limit 20 \watch 1' \
| sudo -u postgres psql test - pgCenter showing live top-like view of Postgres sessions:
pgcenter -U postgres top - CPU profiling using
perf top:sudo perf top --no-children --call-graph=fp --dsos=/usr/lib/postgresql/14/bin/postgres
The following symptoms were observed:
-
performance on the standby gradually drops to critical levels – the response time grows drastically, so user requests would hit timeouts (such as
statement_timeout) if it was a real-life production environment -
performance degrades very fast, basically making the standby unusable
-
the degradation on the standby lasts until the end of the long-lasting transaction on the primary; once that transaction ends, the performance on standby recovers quickly
-
neither CPU nor disk IO is saturated during the problem; moreover, CPU utilization even drops
-
the
pg_stat_slru(available in PostgreSQL 13 and newer) shows enormous numbers of block hits and reads in theSubtransrow) -
the growing number of active sessions on standbys spending time on the
SubtransSLRUwait event (in Postgres 12 and older:SubtransControlLock):When primary has a long-running tx: Without long-running tx:
event | sum event | sum
-----------------------+------- -----------------------+-------
SubtransSLRU | 18662 ClientRead | 19868
ClientRead | 9494 RecoveryWalStream | 1959
BgWriterHibernate | 2041 BgWriterHibernate | 1934
RecoveryWalStream | 2037 WalReceiverMain | 1819
WalReceiverMain | 1935 WALSync | 132
SLRURead | 1252 BgWriterMain | 40
SubtransBuffer | 523 ProcArray | 9
WALSync | 121 DataFileFlush | 3
BgWriterMain | 40 ControlFileSyncUpdate | 3
ProcArray | 8 MessageQueueInternal | 1
BufferContent | 2(profiles collected using pg_wait_sampling)
-
perf topshows a significantly increased number ofLWLockAttemptLock,LWLockRelease, andLWLockWaitListLockcalls:When primary has a long-running tx: Without long-running tx:
+ 1.62% [.] LWLockRelease + 1.83% [.] hash_search_with_hash_value
+ 1.58% [.] LWLockAttemptLock + 1.33% [.] PostgresMain
+ 1.31% [.] SlruSelectLRUPage + 1.29% [.] AllocSetAlloc
+ 1.14% [.] heap_hot_search_buffer + 1.16% [.] LWLockAttemptLock
+ 0.98% [.] hash_search_with_hash_value + 0.83% [.] PinBuffer
0.69% [.] LWLockWaitListLock + 0.78% [.] _bt_compare
+ 0.67% [.] SimpleLruReadPage_ReadOnly + 0.65% [.] SearchCatCache1
0.49% [.] LWLockAcquire 0.50% [.] WaitEventSetWait
0.44% [.] perform_spin_delay 0.46% [.] LockAcquireExtended
0.42% [.] PinBuffer 0.44% [.] hash_bytes
0.38% [.] dopr.constprop.0 0.43% [.] ResourceOwnerReleaseInternal
0.36% [.] LWLockQueueSelf 0.42% [.] LWLockRelease
The picture below visualizes the performance degradation observed on the standby. One can also explore the monitoring dashboards, downloading the following 11-minute Netdata snapshot files and loading them into any Netdata (e.g., using demo setups):
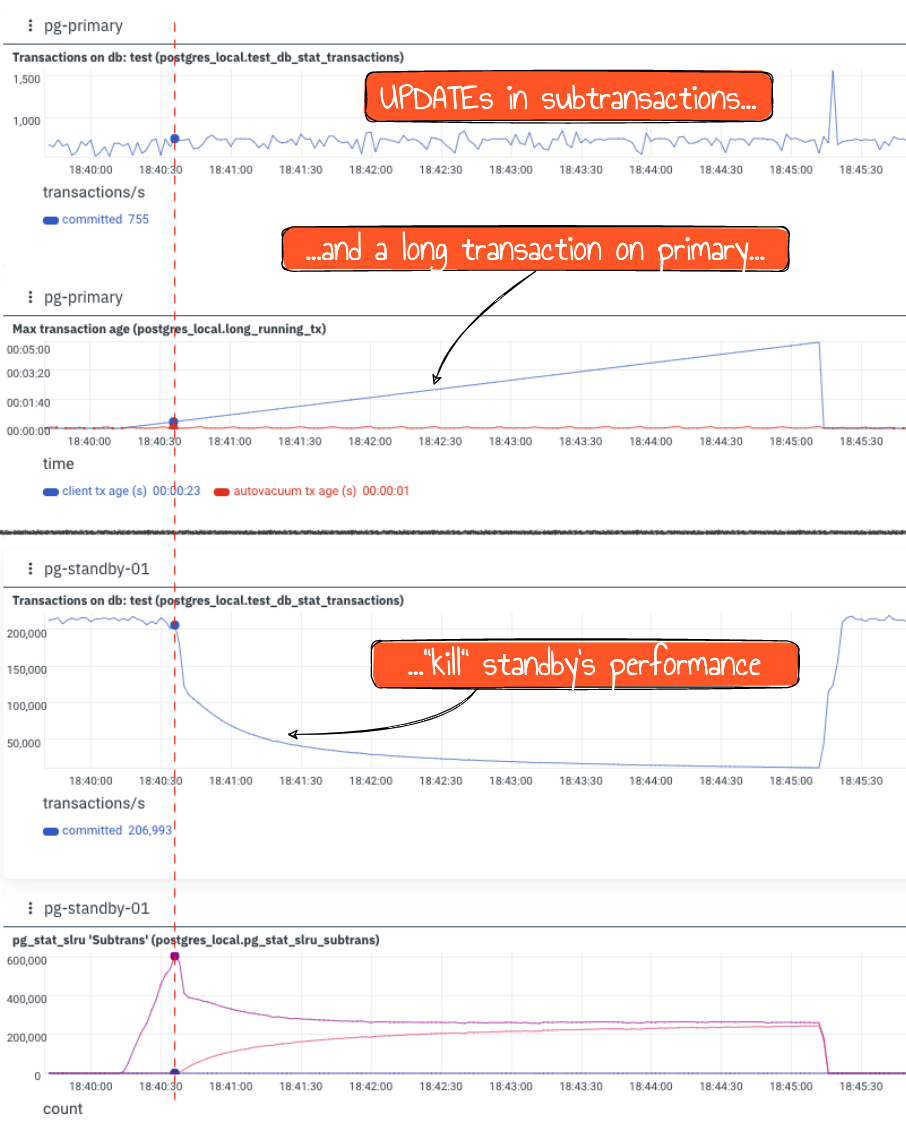
What's happening here? The workload on the primary issues UPDATEs in transactions involving subtransactions. The xmin values in tuples have XID belonging to subtransactions, so each time we read such tuple and need to check its visibility, subtransaction mechanism is involved – there is a global cache for all subtransactions, also SLRU ("simple least-recently-used" cache, see slru.c), but very small – see subtrans.h:
/* Number of SLRU buffers to use for subtrans */
#define NUM_SUBTRANS_BUFFERS 32
The default buffer size is 8 KiB, and each XID is 4 bytes, so this gives us 32 * 8 * 1024 / 4 = 65536. The mechanism of filling the Subtrans SLRU can be found in subtrans.c:
/* We need four bytes per xact */
#define SUBTRANS_XACTS_PER_PAGE (BLCKSZ / sizeof(TransactionId))
#define TransactionIdToPage(xid) ((xid) / (TransactionId) SUBTRANS_XACTS_PER_PAGE)
#define TransactionIdToEntry(xid) ((xid) % (TransactionId) SUBTRANS_XACTS_PER_PAGE)
Subtransaction XIDs may be stored very sparsely in the Subtrans SLRU, as we can see in subtrans.c:
/*
* Make sure that SUBTRANS has room for a newly-allocated XID.
*
* NB: this is called while holding XidGenLock. We want it to be very fast
* most of the time; even when it's not so fast, no actual I/O need happen
* unless we're forced to write out a dirty subtrans page to make room
* in shared memory.
*/
void
ExtendSUBTRANS(TransactionId newestXact)
{
int pageno;
/*
* No work except at first XID of a page. But beware: just after
* wraparound, the first XID of page zero is FirstNormalTransactionId.
*/
if (TransactionIdToEntry(newestXact) != 0 &&
!TransactionIdEquals(newestXact, FirstNormalTransactionId))
return;
pageno = TransactionIdToPage(newestXact);
LWLockAcquire(SubtransSLRULock, LW_EXCLUSIVE);
/* Zero the page */
ZeroSUBTRANSPage(pageno);
LWLockRelease(SubtransSLRULock);
}
In the worst case, a single XID assigned to a subtransaction may solely occupy a whole SLRU page, so the limit of SLRU buffers, NUM_SUBTRANS_BUFFERS, can be reached rather quickly. This suggests that in a system with thousands of TPS, even if a low fraction of those TPS is transactions with subtransactions, it may be a matter of seconds to overflow the cache. In my experiment, it took as few as ~18 seconds from the beginning of the primary's "long" transaction to see a noticeable degradation of TPS.
What happens when Subtrans SLRU is overflown? Let's consult the internal documentation (transam/README):
pg_subtrans is used to check whether the transaction in question is still
running --- the main Xid of a transaction is recorded in ProcGlobal->xids[],
with a copy in PGPROC->xid, but since we allow arbitrary nesting of
subtransactions, we can't fit all Xids in shared memory, so we have to store
them on disk. Note, however, that for each transaction we keep a "cache" of
Xids that are known to be part of the transaction tree, so we can skip looking
at pg_subtrans unless we know the cache has been overflowed. See
storage/ipc/procarray.c for the gory details.
slru.c is the supporting mechanism for both pg_xact and pg_subtrans. It
implements the LRU policy for in-memory buffer pages. The high-level routines
for pg_xact are implemented in transam.c, while the low-level functions are in
clog.c. pg_subtrans is contained completely in subtrans.c.
On the picture above, the last chart shows Subtrans SLRU reads and hits. It is easy to see that the moment when reads start is exactly when standby's TPS starts to degrade. If we check the disk IO, we will not find any real reads or writes – all operations with pg_subtrans are dealing with the page cache. But the fact that it is needed to be checked, as well as the growing number of such checks, affects performance in a really bad way – in our experiment, TPS went down ~20x during 5 minutes, from ~210k down to ~20k.
Again, the meaning of "long" in "long-running transaction" may vary. It may be a few seconds for heavily-loaded systems, so just a regular slow query can very negatively affect standbys' performance.
It is worth noting that indirectly, this problem can be classified as a "scalability" problem because:
- the overhead of using subtransactions is quite low under normal circumstances
- the problem occurs more often when TPS grow and systems need to be vertically scaled – more CPU power is added to handle more TPS
- the problem occurs only on standbys, so moving SELECTs to the primary would solve the problem of the performance degradation itself but would immediately mean that we lose the powerful and very common way for horizontal scaling – offloading read-only workloads to hot standbys
Bottom line: if you expect that your system will need to handle thousands of TPS, and if you offload read-only transactions to standbys, the use of subtransactions may lead to major performance issues and even outages on standbys.
How harmful are Postgres subtransactions?
Do these problems mean that all systems are doomed to experience these problems? Of course, no. Many systems will not reach any of those limits or levels of load when bad events start hitting performance. However, it hurts badly when it happens, and it requires much effort to troubleshoot and fix. One of the sound examples is Amazon's outages during the Prime Day 2018, when Postgres implementation of savepoints managed to be discussed widely (they used Amazon Aurora Postgres, which, of course, is a different DBMS, but as I understand, subtransaction processing there is inherited from Postgres), in various media:
- CNBC, "Amazon’s move off Oracle caused Prime Day outage in one of its biggest warehouses, internal report says":
In one question, engineers were asked why Amazon’s warehouse database didn’t face the same problem "during the previous peak when it was on Oracle." They responded by saying that "Oracle and Aurora PostgreSQL are two different [database] technologies" that handle "savepoints" differently. Savepoints are an important database tool for tracking and recovering individual transactions. On Prime Day, an excessive number of savepoints was created, and Amazon's Aurora software wasn’t able to handle the pressure, slowing down the overall database performance, the report said.
- CIO Dive, "Migration lessons learned: Even Amazon can face mishaps with new tools"
Amazon is about 92% finished migrating off of Oracle's database software and onto its internal Aurora PostgreSQL, according to Werner Vogels, Amazon CTO ... An Amazon warehouse in Ohio experienced the creation of too many savepoints, resulting in a "temporary situation where the database was very slow," according to Vogels.
Later that year, Jeremy Schneider, a member of the AWS RDS team, commented in PostgreSQL mailing list:
...if folks are building high-throughput applications that they expect to scale nicely on PostgreSQL up to 32-core boxes and beyond, I'd suggest avoiding savepoints in any key codepaths that are part of the primary transactional workload (low-latency operations that are executed many times per second).
And then AWS patched the Aurora documentation, so now it has:
LWLock:SubtransControlLock- In this wait event, a session is looking up or manipulating the parent/child relationship between a transaction and a subtransaction. The two most common causes of subtransaction use are savepoints and PL/pgSQL exception blocks. The wait event might occur if there is heavy concurrent querying of data that's simultaneously being updated from within subtransactions. You should investigate whether it is possible to reduce the use of savepoints and exception blocks, or to decrease concurrent queries on the rows being updated.
So, Postgres subtransactions are not harmful at all – if your systems are not heavily loaded. But they can cause really serious incidents, otherwise.
Recommendations and possible future
Recommendation 1: good monitoring
For all systems, I strongly recommend ensuring that monitoring has:
- transaction ID wraparound charts and alerts
- wait event analysis (can be implemented using pgsentinel, pg_wait_sampling, or, at least, if you cannot install those, using periodical sampling of
pg_stat_activity; ad hoc tools like pgCenter or PASH Viewer can be helpful too, but it's important to have something that can collect historical data – incidents may happen suddenly and go away suddenly too, so having historical data is essential for a post mortem analysis) - long-running transactions (what is the age of the oldest transaction at any given time?)
In our opinion, these three items are critical and must be present in any mature Postgres monitoring system.
A nice-to-have item here is a chart (or a few) with metrics from pg_stat_slru, if PostgreSQL version is 13 or newer.
Recommendation 2: check if you have subtransactions
It is recommended to learn if subtransactions are used in your systems. If they are, it does not immediately mean that they need to be eliminated – it all depends on the risks of your particular case. Evaluating such risks is a complex task that requires deep Postgres expertise, so if you need such an analysis, consider hiring a PostgreSQL expert.
If you suspect that problems related to subtransactions may hit you:
- consider adding logging and/or monitoring events for all cases when subtransactions are used; this needs to be done on the application side because Postgres, at least as of version 14beta3 (mid-2021), does not provide observability tooling related to subtransactions yet;
- prepare a mitigation plan – which, depending on the nature of the problem, may include the complete elimination of subtransactions
Recommendation 3: experiment to predict and prevent failures
For mission-critical systems, it is strongly recommended to build a benchmarking environment where the "real workload" may be simulated, and system behavior can be checked under 2x, 5x, 10x load compared to the current numbers.
This can be time-consuming and may require deep expertise too, but it can help engineers predict and prevent other possible problems.
Ideas for PostgreSQL development
Here is a set of ideas for those who are involved in Postgres development and are able to help.
- Andrey Borodin developed a set of patches that allow controlling the sizes of SLRU caches (including Subtrans SLRU) and make the SLRU mechanism more performant. Those patches have an open record in the ongoing commitfest for Postgres 15 development, so if they are approved, it may be very helpful. If you can, consider reviewing them and testing them. We've briefly tested them recently (results), and have plans to continue.
- Postgres observability tooling could be extended:
- it would be really good to understand what transactions are using subtransactions and how large the nesting depth is,
- pageinspect module could be extended to allow checking the contents of the SLRU caches
- Subtranscations could be implemented differently. I understand that it may be very difficult and that I might miss something, but it was a surprise to me to learn that subtransactions are assigned with XID from the same namespace as regular transactions and that those XIDs then are written to tuple headers – as regular XIDs are. It seems that checks and overhead are caused by this design, but at the same time, with the lowest transaction isolation level in Postgres, READ COMMITTED, it is impossible to see anything that is not fully committed by other transactions – so logically, only the main XID matters. It would be really great if only the main transaction's XID was used in tuple headers. (Update: after this article was published, Hannu Krosing commented in Twitter and helped me understand that with using the XID of the main transaction in all tuples and make impossible to have straightforward logic of the
ROLLBACK TO SAVEPOINT.) - UPDATE 2021-08-30: Pengcheng Liu has sent a new patch to the -hackers mailing list, it originally aims to solve Problem 2 (related to
PGPROC_MAX_CACHED_SUBXIDS) but redesigns the work with Subtrans SLRU cache, so it may be helpful to solve Problems 3 and 4 too.
Summary
We explored four particular issues that can be associated with the use of subtransactions:
- higher risks of "XID wraparound" incident associated with higher XID growth
- moderate performance degradation caused by exceeding
PGPROC_MAX_CACHED_SUBXIDS - significant performance degradation caused by engaging Multixact ID mechanism with
SELECT .. FOR UPDATEis used with subtransactions - significant performance degradation on standbys caused by the combination of subtransactions and a long-running transaction on the primary
All problems are easy to reproduce. We have provided recommendations for Postgres DBAs and a wide range of engineers that run systems using Postgres and aim to grow without bottlenecks. The main recommendation is to have strong monitoring (first of all: long-running transactions, wait event sampling, and transaction ID wraparound).
The future work may include additional benchmarks and testing of patches.

DBLab Engine
Instant database branching with O(1) economics.