Database Lab Engine for AWS Marketplace. Fast, fixed-cost branching for your Postgres is just a step away
· 2 min read
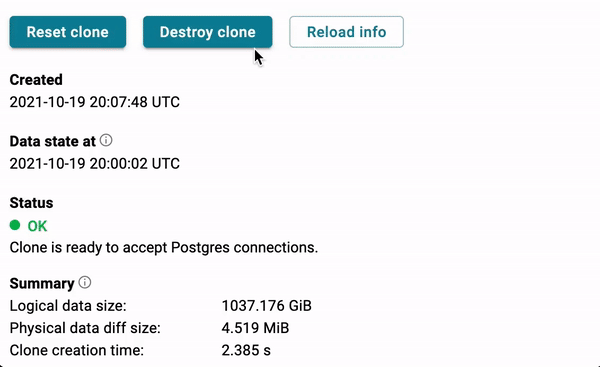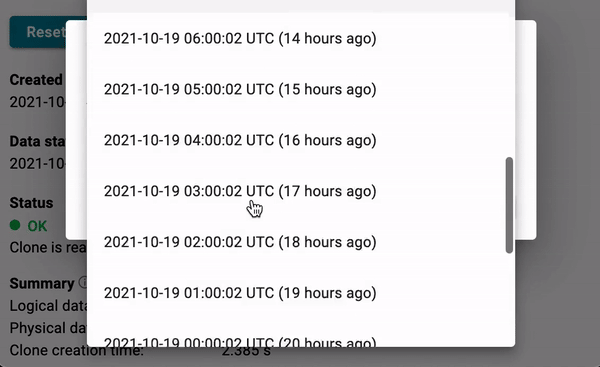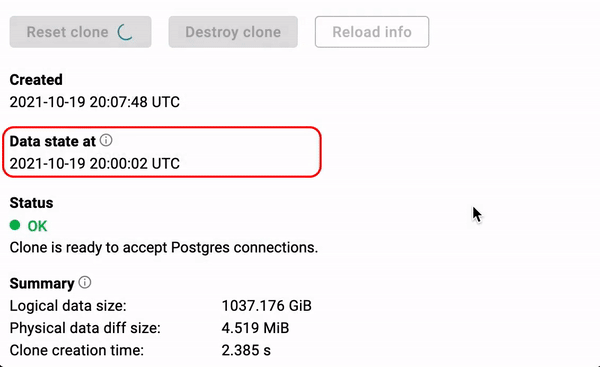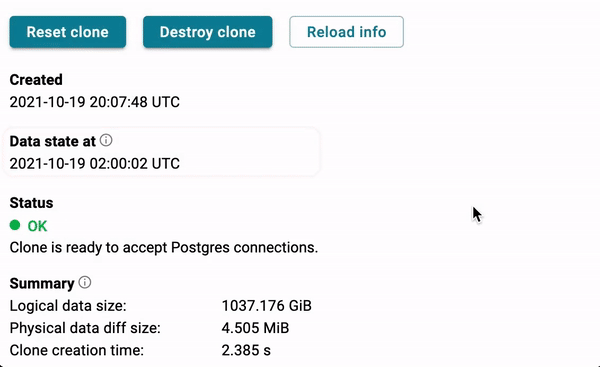
I'm very pleased to announce the very first preview version of Database Lab Engine (DLE) for AWS Marketplace. If you're using AWS, this is the fastest way to have powerful database branching for any database, including RDS and RDS Aurora. But not only RDS: any Postgres and Postgres-compatible database is supported as a source for DLE.
Now, for a fixed price (paying just for one EC2 instance and an EBS volume), you can have dozens of DB clones being provisioned in seconds and delivering independent databases for your Git branches, CI/CD pipelines, as well as manual optimization and testing activities.