Joe bot demo and example
Demonstration
If you have the Slack app installed, try the live demonstration:
- Add the Database Lab community to your Slack: https://slack.postgres.ai/
- Go to the #joe-bot-demo public channel
- Start with the
helpcommand - Explore the schema with
\d, analyze queries usingexplain - Try dropping a column or a whole table using
exec - Ask your colleague to try talking to Joe in parallel, to ensure that your sessions are independent (so your colleague doesn't observe your changes in her/his copy of the database)
- Perform
resetto quickly revert your changes in your own session
The live demonstration is based on a 200 GiB database generated by pgbench.
An example
The goal
Suppose we need to optimize the following query:
select count(*)
from posts
where likes > 10 and created > '2019-10-01';
Use the explain command
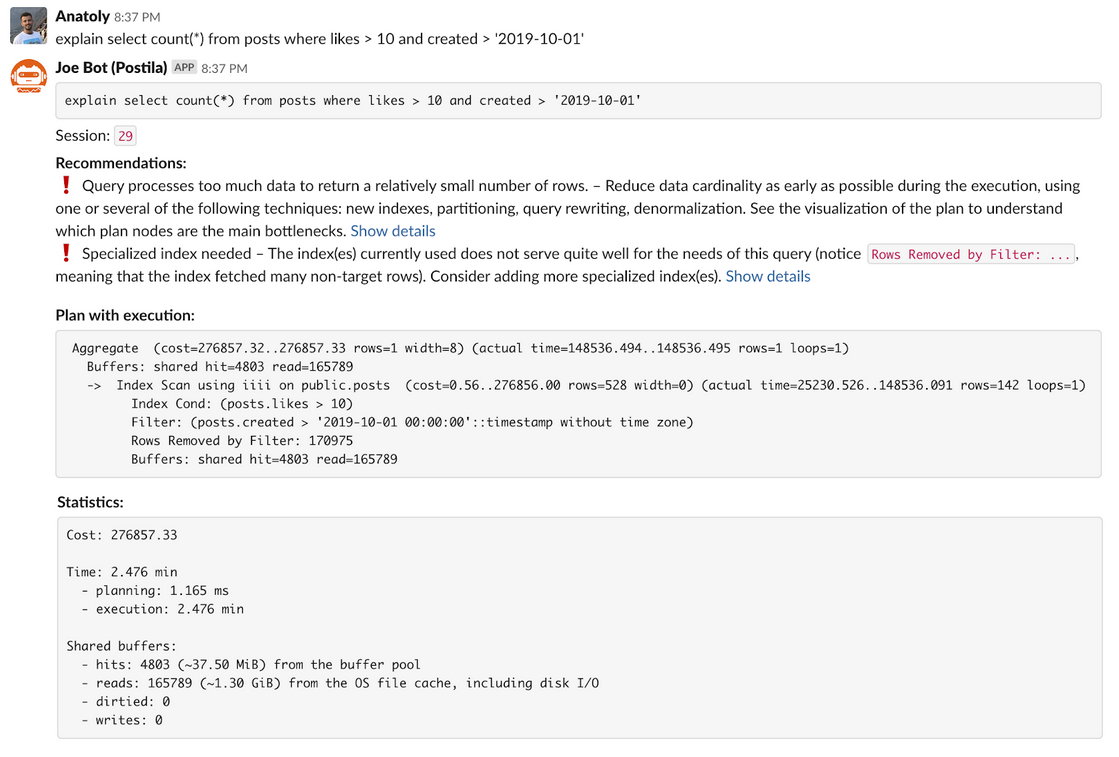
Read the summary
- Execution Time: 2.5 minutes
- Joe bot provides recommendations:
- Query processes too much data to return a relatively small number of rows
- Specialized index needed
- Shared buffers reads: 165789 (~1.30 GiB) from the OS file cache, including disk I/O
Go deeper: analyze the details provided in the execution plan
- An
Index Scanis used - Rows Returned:
142 - Rows Removed by Filter:
170975Aggregate (cost=276857.32..276857.33 rows=1 width=8) (actual time=148536.494..148536.495 rows=1 loops=1)
Buffers: shared hit=4803 read=165789
-> Index Scan using iiii on public.posts (cost=0.56..276856.00 rows=528 width=0) (actual time=25230.526..148536.091 rows=142 loops=1)
Index Cond: (posts.likes > 10)
Filter: (posts.created > '2019-10-01 00:00:00'::timestamp without time zone)
Rows Removed by Filter: 170975
Buffers: shared hit=4803 read=165789 - The query condition partially does not match the index condition
Index Cond: (posts.likes > 10)
Filter: (posts.created > '2019-10-01 00:00:00'::timestamp without time zone) - The conclusion: a specialized index is needed
Optimize: build a new index
-
Using the
execcommand, we are going to create the following new index in the current session:create index improved_ix_posts on posts(likes, created desc);
Check the results: explain the query again
- Run the
explaincommand once again:explain select count(*) from posts where likes > 10 and created > '2019-10-01' - The result:
Time: 157.236 ms
- planning: 1.185 ms
- execution: 156.051 ms
Shared buffers:
- hits: 69 (~552.00 KiB) from the buffer pool
- reads: 778 (~6.10 MiB) from the OS file cache, including disk I/O
- dirtied: 0
- writes: 0
Aggregate (cost=4147.01..4147.02 rows=1 width=8) (actual time=155.973..155.974 rows=1 loops=1)
Buffers: shared hit=69 read=778
-> Index Only Scan using improved_ix_posts on public.posts (cost=0.56..4145.69 rows=528 width=0) (actual time=3.981..155.870 rows=142 loops=1)
Index Cond: ((posts.likes > 10) AND (posts.created > '2019-10-01 00:00:00'::timestamp without time zone))
Heap Fetches: 142
Buffers: shared hit=69 read=778 - Comparing to the previous analysis:
- Index Only Scan instead of Index Scan
- Execution Time: ~ 150 ms – 1000x faster
- Shared buffers reads: 778 (~6.10 MiB) from the OS file cache, including disk I/O – 218x less data