Zero-downtime Postgres schema migrations need this: lock_timeout and retries

Zero-downtime database schema migrations
This is one of those topics that hit experienced Postgres DBAs badly. So badly that hypothetical Socrates of 21th century could be one of those Postgres DBAs and the words "I know that I know nothing" would sound natural. I've seen dozens of projects with busy Postgres setups serving lots of TPS, in mission-critical systems in zillion-dollar companies, where database engineers were thinking that they are experienced and know what they are doing – and then suddenly this, quite a basic topic, made them say "ouch" and quickly fix their DDL deploy systems. Well, let's be frank: I was in this position myself, learning this after more than 10 (!) years of Postgres experience.
I'm sure some of you know this very well – if so, scroll down to see some bits of advanced material on the matter. However, I'm 100% sure that many of my readers will be really surprised right now.
We won't talk about "how to change a column's data type" or "how to add a foreign key" – those questions are all interesting too, and there are efforts to document and automate each of such steps for heavily-loaded systems with strict uptime requirements (a great example here is GitLab's "Migration Style Guide"). Instead, we will discuss something that affects any Postgres setup where schema needs to be changed from time to time, where downtime is considered as a huge problem, where DDLs are automated in one way or another (I mean DB migration tools such as Flyway, Sqitch, Liquibase, Ruby on Rails AR DB Migrations, and so on), but where DDLs are deployed without certain trick, so downtime can happen suddenly and unpredictably. Even if TPS numbers are not big. Without that trick in place, anyone using Postgres can (and will) hit that wall one day. Therefore, any engineer working with Postgres should know this trick and, perhaps, implement it in all systems to prevent downtime.
It is time to dive into technical details...
Problem demonstration
Let's jump straight to the point: when you deploy database schema changes, you are not protected from system downtime even if you have very high-level automation but don't use very low values of lock_timeout (or statement_timeout) to acquire a lock on the DB objects that are subject to change and do not implement some kind of retry logic.
To demonstrate it, let's create a table with a single row:
create table test as select 1 as i;
Next, we need three psql terminals.
- In the first, open transaction (for our purposes, default isolation level, READ COMMITTED, is enough), read from the table, and keep the session in the "idle in transaction" state:
begin;
select * from test; - In the second, we will try to "deploy" some DDL – for example, adding the NOT NULL constraint to the
icolumn (obviously, this action is going to be blocked, waiting for the transaction with SELECT to be finished – either committed or rolled back):alter table test alter column i set not null; - Finally, in the third psql, let's try to read from the table:
select * from test;
This may be surprising, but the last action "hangs" – the SELECT command doesn't return anything. Why?
To see what's happening we'll open one more, the fourth psql terminal, and use the lock analysis snippet that returns "a forest of locking trees":
\timing on
set statement_timeout to '100ms';
with recursive activity as (
select
pg_blocking_pids(pid) blocked_by,
*,
age(clock_timestamp(), xact_start)::interval(0) as tx_age,
age(clock_timestamp(), state_change)::interval(0) as state_age
from pg_stat_activity
where state is distinct from 'idle'
), blockers as (
select
array_agg(distinct c order by c) as pids
from (
select unnest(blocked_by)
from activity
) as dt(c)
), tree as (
select
activity.*,
1 as level,
activity.pid as top_blocker_pid,
array[activity.pid] as path,
array[activity.pid]::int[] as all_blockers_above
from activity, blockers
where
array[pid] <@ blockers.pids
and blocked_by = '{}'::int[]
union all
select
activity.*,
tree.level + 1 as level,
tree.top_blocker_pid,
path || array[activity.pid] as path,
tree.all_blockers_above || array_agg(activity.pid) over () as all_blockers_above
from activity, tree
where
not array[activity.pid] <@ tree.all_blockers_above
and activity.blocked_by <> '{}'::int[]
and activity.blocked_by <@ tree.all_blockers_above
)
select
pid,
blocked_by,
tx_age,
state_age,
replace(state, 'idle in transaction', 'idletx') state,
datname,
usename,
format('%s:%s', wait_event_type, wait_event) as wait,
(select count(distinct t1.pid) from tree t1 where array[tree.pid] <@ t1.path and t1.pid <> tree.pid) as blkd,
format(
'%s %s%s',
lpad('[' || pid::text || ']', 7, ' '),
repeat('.', level - 1) || case when level > 1 then ' ' end,
query
)
from tree
order by top_blocker_pid, level, pid
\watch 1
We'll see something like this:
pid | blocked_by | tx_age | state_age | state | … | wait | blkd | format
-----+------------+----------+-----------+--------+----------+-------------------+------+---------------------------------------------------------
48 | {} | 14:26:52 | 14:26:50 | idletx | … | Client:ClientRead | 2 | [48] select * from test;
78 | {48} | 14:26:43 | 14:26:43 | active | … | Lock:relation | 1 | [78] . alter table test alter column i set not null;
224 | {78} | 14:26:40 | 14:26:40 | active | … | Lock:relation | 0 | [224] .. select * from test;
(3 rows)
What's the problem we see here? Our DDL (alter table ...) cannot acquire a lock on the table. It is waiting for another transaction to complete (a rule of thumb to remember: all DB-level locks a transaction acquired, are released only when transaction finishes – in other words, only when it is either committed or rolled back). Interesting, that this transaction (pid=48) hasn't changed the data – it holds an ACCESS SHARE lock on the table as we can see inspecting pg_locks:
test=# select locktype, relation, virtualxid, transactionid, virtualtransaction, pid, mode, granted from pg_locks where pid = 48;
locktype | relation | virtualxid | transactionid | virtualtransaction | pid | mode | granted
------------+----------+------------+---------------+--------------------+-----+-----------------+---------
virtualxid | | 3/11 | | 3/11 | 48 | ExclusiveLock | t
relation | 24869 | | | 3/11 | 48 | AccessShareLock | t
(2 rows)
The DDL we're trying to apply needs an ACCESS EXCLUSIVE lock on the table, and it conflicts with ACCESS SHARE, as we can see in this visualization of table-level locks presented in PostgreSQL documentation (drawings and comments are mine):
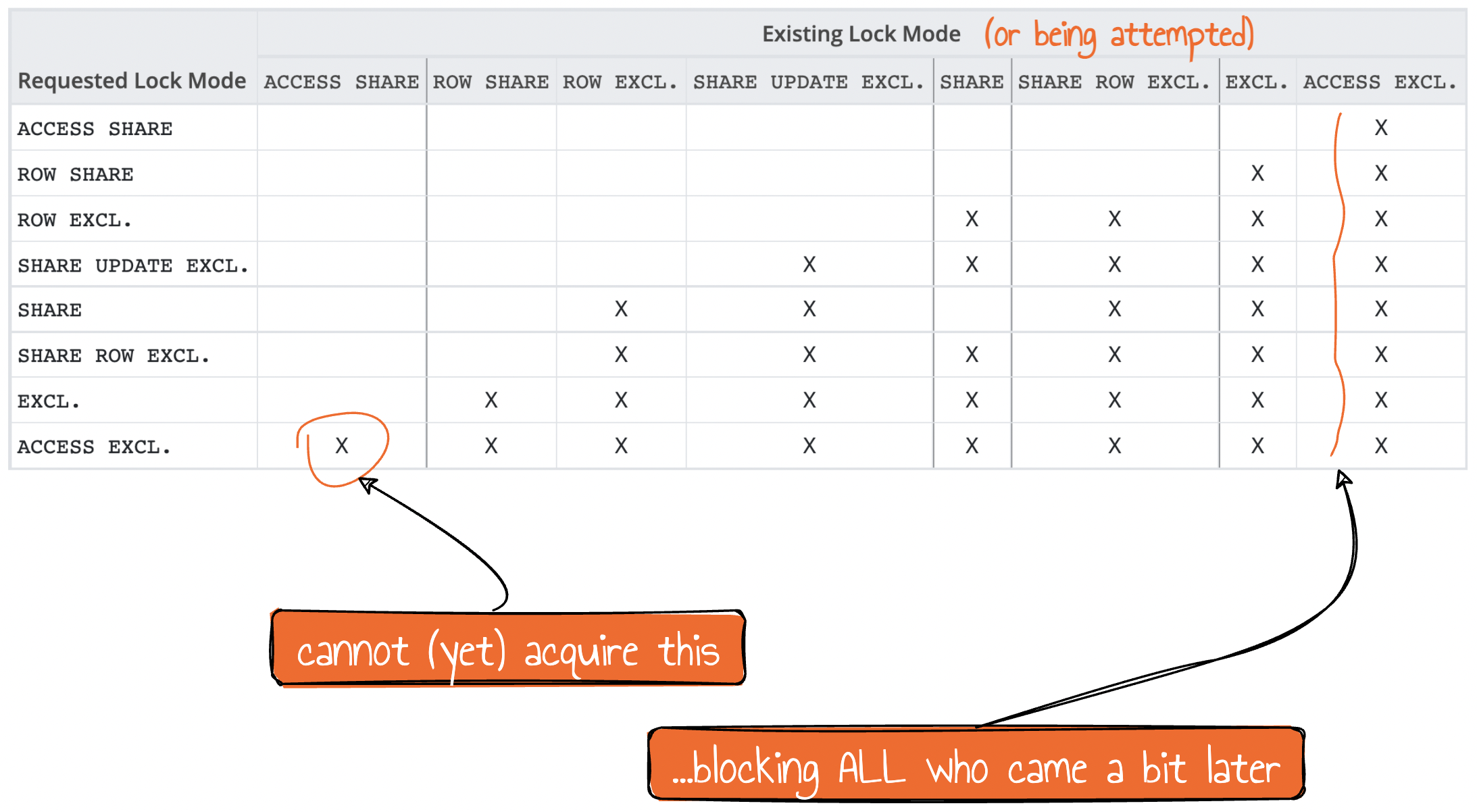
So if there are long-running transactions involving our target table (even regular SELECTs lasting significant time), such transactions block DDL. This itself may be a problem, especially if you wrap your DDL into some transaction (Postgres provides excellent capabilities to make almost all DDLs ACID-compliant), and have some other actions in that transaction that have already acquired some other locks – those locks would be held, potentially affecting other sessions. This is the exact reason why DB schema migration transactions should be carefully sculptured and tested.
But there is another, more interesting problem here: look at the third session (pid=224), where a SELECT attempt was made to the same table after the DDL attempt has started:
pid | blocked_by | tx_age | state_age | state | … | wait | blkd | format
-----+------------+----------+-----------+--------+----------+-------------------+------+---------------------------------------------------------
224 | {78} | 14:26:40 | 14:26:40 | active | … | Lock:relation | 0 | [224] .. select * from test;
(3 rows)
Our session with a DDL attempt (pid=78), while waiting to acquire the ACCESS EXCLUSIVE lock it needs, starts blocking others. It's blocking even read-only transactions that deal with our table – basically, any work with this table becomes now impossible! This is exactly the thing that triggers the "aha" or "ouch" moment for many DBAs.
Lesson learned: if you just fire your DDL to a busy server, not protecting it with strict timeout settings, then one day you may find that your attempt to apply some DDL put the system down. Everyone who wants to avoid it needs protection – and this protection can be done via using low timeout values (either lock_timeout or statement_timeout).
Graceful schema changes: lock_timeout and retries
In his article "How to run short ALTER TABLE without long locking concurrent queries", Hubert "depesz" Lubaczewski describes this problem and proposes a solution. It consists of two ideas:
- Do not allow our DDL to be too long in the "waiting" state:
set statement_timeout = '50ms'; - Since now the DDL can fail fast, implement retries:
while true; do date; psql -qX -v ON_ERROR_STOP=1 -f alter.sql && break; sleep 1; done
Of course, in some cases, we need to allow our DDL to work longer than '50ms' – for such cases, we could acquire a lock on the table explicitly (calling lock table ...;), and then change the value of statement_timeout to 0 or something that could be enough for the operation – here is the snippet from the same article:
begin;
set statement_timeout = 50;
lock table only test in ACCESS EXCLUSIVE MODE;
set statement_timeout = 0;
alter table test ....;
-- do whatever you want, timeout is removed.
commit;
Since Postgres 9.3, instead of statement_timeout, we can use lock_timeout – it will affect only our attempts to acquire a lock, quite handy.
What if we need to combine multiple DDL commands in a single transaction? PostgreSQL is very powerful here, allowing virtually any DDL to be executed in transactions, to achieve atomicity. But in this case, if we successfully performed one action, but failed to acquire a lock of the next one, it means that whole our transaction gets a ROLLBACK. This can be improved using one of the following ideas:
-
Acquire all locks we need at the very beginning of the transaction, explicitly (pessimistic locking). If we cannot acquire any of them, the transaction fails, and we retry it. This allows us to avoid real operations that need to be rollbacked – when we start doing the actual changes, we already have all the locks we need, so the transaction is very likely to be committed. Here is some abstract example:
begin;
set local lock_timeout to '50ms';
lock table only t1 in access exclusive mode;
lock table only t2 in access exclusive mode;
alter table t1 ...;
alter table t2 ...;
commit; -
Use subtransactions: either explicitly using word
SAVEPOINT, or usingBEGIN / EXCEPTION WHEN .. / ENDblock in PL/pgSQL code, benefit from the ability to roll back only a part of the changes. This idea was proposed (in the form of PL/pgSQL code) by Mikhail Velikikh in the same article's comments section:do $do$
declare
lock_timeout constant text := '50ms';
max_attempts constant int := 1000;
ddl_completed boolean := false;
begin
perform set_config('lock_timeout', lock_timeout, false);
for i in 1..max_attempts loop
begin
execute 'alter table test add column whatever2 int4';
ddl_completed := true;
exit;
exception
when lock_not_available then
null;
end;
end loop;
if ddl_completed then
raise info 'DDL has been successfully completed';
else
raise exception 'Failed to perform DDL';
end if;
end $do$;
I find both ideas very useful and worth considering. The use of subtransactions to implement retries for transaction parts, not for the whole transaction is especially appealing (again: PL/pgSQL is not a requirement – if you don't prefer it, you may use regular SQL and SAVEPOINTs).
However, subtransactions may imply some risk.
On the risks related to subtransactions
Under certain circumstances, subtransactions can lead to performance degradation. Some of such risks were recently explored in our blog in detail. In a few words, even a low number of XIDs (32-bit transaction ID; subtransactions also use the same namespace of transaction IDs as regular transactions) assigned to unfinished subtransactions, combined with the ongoing long-running transaction on the primary, may lead to drastic performance degradation on standbys. In the mentioned article it was explored in the section "Problem 4: Subtrans SLRU overflow".
But if we use just a single SAVEPOINT, is this still the case – may it happen that we use many XIDs and have risks to get into trouble? The answer is "potentially yes". Let's see what happens if we have a single SAVEPOINT, but experience multiple retries:
test=# create table test(i int8);
CREATE TABLE
test=# select pg_current_xact_id(); -- txid_current() in older PG versions
pg_current_xact_id
--------------------
test=# drop table test;
DROP TABLE
test=# create table test(i int8);
CREATE TABLE
test=# select pg_current_xact_id(); -- txid_current() in older PG versions
pg_current_xact_id
--------------------
1551685670
(1 row)
test=# begin;
BEGIN
test=*# select pg_current_xact_id();
pg_current_xact_id
--------------------
1551685671
(1 row)
test=*# savepoint s1;
SAVEPOINT
test=*# insert into test select 1;
INSERT 0 1
test=*# rollback to s1;
ROLLBACK
test=*# insert into test select 2;
INSERT 0 1
test=*# rollback to s1;
ROLLBACK
test=*# insert into test select 3;
INSERT 0 1
test=*# commit;
COMMIT
test=# select pg_current_xact_id();
pg_current_xact_id
--------------------
1551685675
(1 row)
As we see, the global XID value grown more than by 1 during our transaction – every time we had a ROLLBACK for our subtransaction, it got a new XID assigned. Let's double-check it looking at the xmin hidden column (any tuple in Postgres has a few hidden rows – for details, see "5.5. System Columns" in the official documentation) using the pageinspect extension, which allows seeing dead tuples too:
test=# select xmin, * from test;
xmin | i
------------+---
1551685674 | 3
(1 row)
test=# create extension pageinspect;
CREATE EXTENSION
test=# select lp, t_xmin, t_xmax, t_ctid, t_data from heap_page_items(get_raw_page('test', 0));
lp | t_xmin | t_xmax | t_ctid | t_data
----+------------+--------+--------+--------------------
1 | 1551685672 | 0 | (0,1) | \x0100000000000000
2 | 1551685673 | 0 | (0,2) | \x0200000000000000
3 | 1551685674 | 0 | (0,3) | \x0300000000000000
(3 rows)
The first tuples (with 1 and 2 in the i column) are dead because right after INSERT we had ROLLBACK (partial, applied to subtransaction only). The t_xmin column contains XID of the transaction (or subtransaction, in our case) in which the tuple was created. As we can see here, we have used 1551685672, 1551685673, 1551685674 – and the transaction itself had XID = 1551685671 – so each time we ROLLBACK to our single savepoint, we have a new XID assigned.
This means, that risks associated with the use of subtransactions are significant even if we have only one SAVEPOINT. However, worth noting that only systems with high TPS might experience issues – it all depends on the particular situation.
Another drawback of subtransaction-based retries compared to whole-transaction retries is that the former, potentially, have a bigger impact on autovacuum's work on cleaning up dead tuples. We'll analyze this problem below.
That being said, I cannot say that I'd suggest everyone getting rid of subtransactions completely. I still find the idea of partial rollbacks for retries when deploying DDL useful and viable. However, if you have, for example, a system 10,000 TPS and risks of long-running transaction (say, 1 minute or more) – I'd definitely be very careful with the use of subtransactions. If you have PostgreSQL 13+, the good news is that pg_stat_slru can be very helpful – if you see reads for Subtrans SLRU on standby, it's a strong signal that SLRU is overflown and such standby server's performance degradation, if any, is caused by that.
Exponential backoff and jitter
The original PL/pgSQL snippet proposed by Mikhail Velikikh discussed above is great, but it lacks an important part – delays between attempts of lock acquisition. Let's conduct an experiment, at least in our mind (because it's trivial – but if you wish, you can practice it, of course). Imagine we have a SELECT-only workload and all SELECTs to table test are sub-millisecond in terms of duration. Say, their average duration is 0.1 ms. And in parallel, we've opened a transaction, executed a SELECT to test (acquiring an ACCESS SHARE lock as described above), and keep that session in the "idle in transaction" state. Now, we're trying to deploy some DDL using that snippet, with lock_timeout set to 50ms. What happens with the average duration of SELECTs? Right, it will drop to almost 50 milliseconds! Just because most of them will be blocked by our attempts.
But if we add a delay after each attempt – say, 1 second – only some of SELECTs will be affected. Roughly, each second we will introduce a "stressful" lock acquisition attempt for only 50 milliseconds (being more precise, this will happen every ~1050 milliseconds). So most of the SELECTs won't be affected at all, and the average duration of them will rise only slightly. I'm leaving this for my readers to experiment and see the exact numbers.
These delays also help us increase our chances of success. We have a limited number of attempts (in Mikhail's snippet, it's 1000) after which we have the transaction aborted, hence we declare the deployment failure and postpone it for a while (or repeat it right away – depending on the tactics we define). If we retry without delays, we have some 50 ms * 1000 = 50 seconds to succeed. if during that period, the long-running transaction blocked us, it's a failure. With 1 second delay and 1000 retries, we have ~1050 ms * 1000 = ~17.5 minutes, during which the chances that a long-running transactiona ends, unblocking us, are much higher. On the other hand, if we, instead of a single long-running transaction, have a series of, say 10-second transitions that happen without delays for a very long period, the chances of failure are again high – and in this case, attempts without delays would allow us "squeeze" into the sequence of the "blocking" transactions.
In the blog post "Exponential Backoff And Jitter", Marc Brooker (Amazon Web Services) explores the topic of locking attempts in environments with a high level of contention. Long story short, implementing delays with two additional "ingredients" helps succeed with less work done (fewer attempts, hence less stress on the system). Those ingredients are:
- exponential backoff – multiply backoff (the pause duration) by a constant after each attempt, up to some maximum value:
sleep = min(cap, base * 2 ** attempt) - jitter – use a randomized value in the sleep function:
sleep = random(between(0, min(cap, base * 2 ** attempt))
If you're interested in details, I encourage you to read the blog post. It also has the link to the GitHub repo, where you can find the source code for experimenting: https://github.com/aws-samples/aws-arch-backoff-simulator.
Let's rework the PL/pgSQL snippet for deploying DDLs to introduce the exponential backup with jitter (it's quite easy to translate this snippet to the "pure SQL" one using SAVEPOINTs, or to "whole transaction" approach without subtransactions using retries based on your language of chouse; so won't provide those snippets here):
do $do$
declare
lock_timeout constant text := '50ms';
max_attempts constant int := 30;
ddl_completed boolean := false;
cap_ms bigint := 60000;
base_ms bigint := 10;
delay_ms bigint := NULL;
begin
perform set_config('lock_timeout', lock_timeout, false);
for i in 1..max_attempts loop
begin
alter table test add column whatever2 int4;
ddl_completed := true;
exit;
exception when lock_not_available then
raise warning 'attempt %/% to lock table "test" failed', i, max_attempts;
delay_ms := round(random() * least(cap_ms, base_ms * 2 ^ i));
raise debug 'delay %/%: % ms', i, max_attempts, delay_ms;
perform pg_sleep(delay_ms::numeric / 1000);
end;
end loop;
if ddl_completed then
raise info 'table "test" successfully altered';
else
raise exception 'failed to alter table "test"';
end if;
end $do$;
An example of the output showing how the delay has grown until we successfully ALTER the table on the 12th attempt:
WARNING: attempt 1/30 to lock table "test" failed
DEBUG: delay: 10 ms
WARNING: attempt 2/30 to lock table "test" failed
DEBUG: delay: 38 ms
WARNING: attempt 3/30 to lock table "test" failed
DEBUG: delay: 44 ms
WARNING: attempt 4/30 to lock table "test" failed
DEBUG: delay: 43 ms
WARNING: attempt 5/30 to lock table "test" failed
DEBUG: delay: 151 ms
WARNING: attempt 6/30 to lock table "test" failed
DEBUG: delay: 500 ms
WARNING: attempt 7/30 to lock table "test" failed
DEBUG: delay: 678 ms
WARNING: attempt 8/30 to lock table "test" failed
DEBUG: delay: 1107 ms
WARNING: attempt 9/30 to lock table "test" failed
DEBUG: delay: 2896 ms
WARNING: attempt 10/30 to lock table "test" failed
DEBUG: delay: 9197 ms
WARNING: attempt 11/30 to lock table "test" failed
DEBUG: delay: 13982 ms
INFO: table "test" successfully altered
Here I reduced the number of attempts to 30 and defined the maximum sleep time as 60000 ms (1 minute). I also got rid of dynamic SQL (it's not really needed here unless you want to pass the DDL dynamically) and added some diagnostics, including reporting the sleep time via raise debug – you can use set client_min_messages to debug; to see what's happening.
Of course, YMMV – it's worth spending some time learning a particular system's behavior and adjusting the parameters.
What else to be aware of: long-running transactions, xmin horizon
You may have a reasonable question: what if instead retries, we just implement some pre-checking mechanism that would ensure that there are not active locks to the table we're going to change, so it is a good time to start DDL. But imagine you have many clients that are very frequently sending quite lightweight (say, lasting 1 ms) SELECTs. So frequently that at any given time, your pre-check would answer "no, there are locks". In this situation, your automation for DDL deployment will never succeed. At the same time, retries with lock_timeout = '50ms' will be successful after a millisecond or two – once all transactions started before our DDL attempt has finished, we acquire the lock we need. And we don't care about the transactions started after us – remember, they are in the "waiting queue", so we have as much as 50 milliseconds (or more if you increase it) to complete the attempt.
However, pre-checks can be very useful. For example, it totally makes sense to check if there are ongoing long-running transactions involving the DB objects we're going to change. Moreover, it makes sense to check all long-running transactions before proceeding with DDL deployment, especially if your retry logic is based on the use of subtransactions – to avoid Subtrans SLRU overflow on standbys. For example, one of the possible tactics could be: if we see a long-running transaction lasting more than 1 minute, we postpone the schema change or interrupt that transaction right before the change attempts.
Another aspect that needs to be taken into account is the so-called "xmin horizon". In pg_stat_activity, you can see it in the backend_xmin column – the minimum of all values defines this horizon (and if you have standbys with hot_standby_feedback = 'on', then you need to take into account sessions on them too). This value represents the oldest XID that created tuples that belong to the "oldest" snapshot being held by a session. You can use the age(..) function to see the age (integer, delta between current XID and oldest snapshot's xmin):
select max(age(backend_xmin)) from pg_stat_activity;
The bigger this value is, the older snapshot is being held, the more it affects [auto]vacuuming. The thing is that VACUUM can delete dead tuples that only became dead before that snapshot's XID. Therefore, if we use subtransaction-based retries, and our transaction containing subtransactions lasts long (say, 1 hour), it may lead to the accumulation of significant numbers of dead tuples in all tables in the database, which eventually leads to higher bloat and as a result, performance degradation and excessive disk space usage. This is another argument in favor of whole-transaction retries – that approach doesn't have this drawback.
Recommendations
- Be careful with running DDL in heavily-loaded systems and in systems with long-running transactions. Use low
lock_timeoutvalues and retries to deploy schema changes gracefully. - Be careful with subtransactions. They can be very useful, but:
- may suddenly cause painful performance issues at some point if workloads grow – if you do use them and run PostgreSQL 13 or newer, add
pg_stat_slruto your monitoring system and watch for Subtrans SLRU reads; - if the transaction containing subtransactions lasts long, it might contribute to the bloat growth of all tables in the database.
- may suddenly cause painful performance issues at some point if workloads grow – if you do use them and run PostgreSQL 13 or newer, add
- Exponential backup and jitter can help achieve results faster and with fewer attempts – consider using them with or without subtransactions involved.

DBLab Engine
Instant database branching with O(1) economics.