Let's talk about relation-level locks and various confusions, surprises and what is worth to remember in practice.
The key page in Postgres docs describing relation-level locks is here: https://www.postgresql.org/docs/current/explicit-locking.html#LOCKING-TABLES
This page in the docs is called "13.3. Explicit Locking" and it might cause confusion because it talks about implicit locking (e.g., if you run a DML or DDL, locks are applied implicitly; while if you execute LOCK or SELECT .. FOR UPDATE, you explicitly request locks to be acquired). However, this might be just my own terminology bias.
This page has a useful "Table 13.2. Conflicting Lock Modes" that can help understand how a lock acquisition can be blocked by another, already acquired or pending (!) lock:
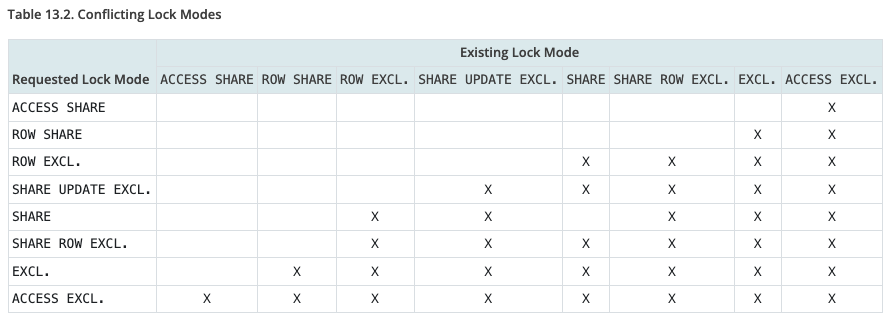
A possible confusion here is the word "row" used in some lock modes – we shouldn't think that those modes are row-level. They are still relation-level. There is a special concept of row-level locks, we'll dive into that separately. This confusion is covered in the docs though:
Remember that all of these lock modes are table-level locks, even if the name contains the word "row"; the names of the lock modes are historical.
Back to the table above, there is a very useful transformation of it in old blog post by Marco Slot, "PostgreSQL rocks, except when it blocks: Understanding locks" (2018, https://citusdata.com/blog/2018/02/15/when-postgresql-blocks/) -- it's incomplete, but speaks common operations and can be used as quick reference:
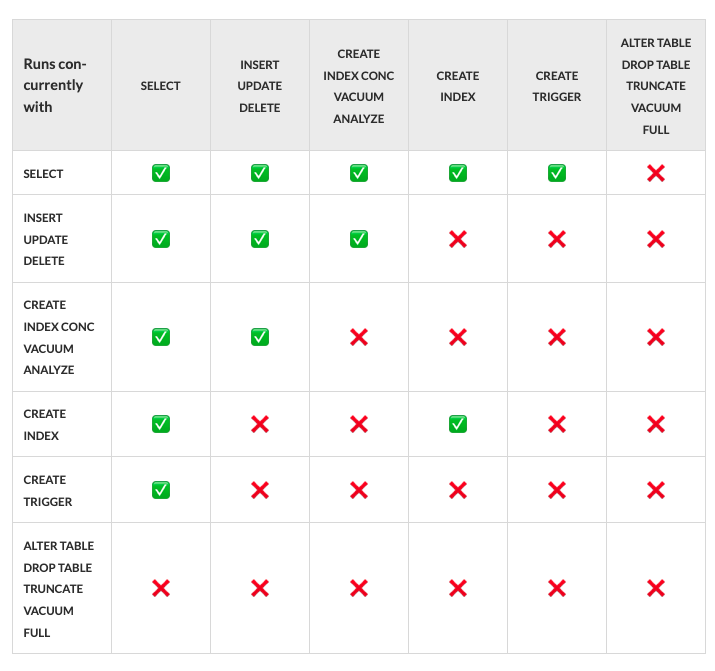
Next, another terminology confusion might come from reading the section, "13.3.1. Table-Level Locks". Let's not be confused, it talks not only about tables, but rather relations.
In Postgres, the word "relation" can be applied to many objects, we can see it looking at the docs for pg_class.relkind (https://postgresql.org/docs/current/catalog-pg-class.html):
r = ordinary table, i = index, S = sequence, t = TOAST table, v = view, m = materialized view, c = composite type, f = foreign table, p = partitioned table, I = partitioned index

